Info
新版网站会员 即将涨价;已支持老用户续费~
Tip
本文有视频版:学习数据结构和算法的框架思维。建议关注我的 B 站账号,我会用视频领读的方式带大家学习那些稍有难度的算法技巧。
这是好久之前的一篇文章 学习数据结构和算法的框架思维 的修订版。之前那篇文章收到广泛好评,没看过也没关系,这篇文章会涵盖之前的所有内容,并且会举很多代码的实例,教你如何使用框架思维。
首先,这里讲的都是普通的数据结构,咱不是搞算法竞赛的,咱的目的是迅速提升算法能力,培养算法思维,真没必要整太偏太怪的题目。另外,以下是我个人的经验的总结,没有哪本算法书会写这些东西,所以请读者试着理解我的角度,别纠结于细节问题,因为这篇文章就是希望帮你对数据结构和算法建立一个框架性的认识。
从整体到细节,自顶向下,从抽象到具体的框架思维是通用的,不只是学习数据结构和算法,学习其他任何知识都是高效的。
一、数据结构的存储方式
数据结构的存储方式只有两种:数组(顺序存储)和链表(链式存储)。
这句话怎么理解,不是还有散列表、栈、队列、堆、树、图等等各种数据结构吗?
我们分析问题,一定要有递归的思想,自顶向下,从抽象到具体。你上来就列出这么多,那些都属于「上层建筑」,而数组和链表才是「结构基础」。因为那些多样化的数据结构,究其源头,都是在链表或者数组上的特殊操作,API 不同而已。
比如说「队列」、「栈」这两种数据结构既可以使用链表也可以使用数组实现。用数组实现,就要处理扩容缩容的问题;用链表实现,没有这个问题,但需要更多的内存空间存储节点指针。
「图」的两种表示方法,邻接表就是链表,邻接矩阵就是二维数组。邻接矩阵判断连通性迅速,并可以进行矩阵运算解决一些问题,但是如果图比较稀疏的话很耗费空间。邻接表比较节省空间,但是很多操作的效率上肯定比不过邻接矩阵。
「散列表」就是通过散列函数把键映射到一个大数组里。而且对于解决散列冲突的方法,拉链法需要链表特性,操作简单,但需要额外的空间存储指针;线性探查法就需要数组特性,以便连续寻址,不需要指针的存储空间,但操作稍微复杂些。
「树」,用数组实现就是「堆」,因为「堆」是一个完全二叉树,用数组存储不需要节点指针,操作也比较简单;用链表实现就是很常见的那种「树」,因为不一定是完全二叉树,所以不适合用数组存储。为此,在这种链表「树」结构之上,又衍生出各种巧妙的设计,比如二叉搜索树、AVL 树、红黑树、区间树、B 树等等,以应对不同的问题。
了解 Redis 数据库的朋友可能也知道,Redis 提供列表、字符串、集合等等几种常用数据结构,但是对于每种数据结构,底层的存储方式都至少有两种,以便于根据存储数据的实际情况使用合适的存储方式。
综上,数据结构种类很多,甚至你也可以发明自己的数据结构,但是底层存储无非数组或者链表,二者的优缺点如下:
数组由于是紧凑连续存储,可以随机访问,通过索引快速找到对应元素,而且相对节约存储空间。但正因为连续存储,内存空间必须一次性分配够,所以说数组如果要扩容,需要重新分配一块更大的空间,再把数据全部复制过去,时间复杂度 O(N);而且你如果想在数组中间进行插入和删除,每次必须搬移后面的所有数据以保持连续,时间复杂度 O(N)。
链表因为元素不连续,而是靠指针指向下一个元素的位置,所以不存在数组的扩容问题;如果知道某一元素的前驱和后驱,操作指针即可删除该元素或者插入新元素,时间复杂度 O(1)。但是正因为存储空间不连续,你无法根据一个索引算出对应元素的地址,所以不能随机访问;而且由于每个元素必须存储指向前后元素位置的指针,会消耗相对更多的储存空间。
二、数据结构的基本操作
对于任何数据结构,其基本操作无非遍历 + 访问,再具体一点就是:增删查改。
数据结构种类很多,但它们存在的目的都是在不同的应用场景,尽可能高效地增删查改。话说这不就是数据结构的使命么?
如何遍历 + 访问?我们仍然从最高层来看,各种数据结构的遍历 + 访问无非两种形式:线性的和非线性的。
线性就是 for/while 迭代为代表,非线性就是递归为代表。再具体一步,无非以下几种框架:
数组遍历框架,典型的线性迭代结构:
void traverse(int[] arr) {
for (int i = 0; i < arr.length; i++) {
// 迭代访问 arr[i]
}
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
void traverse(vector<int>& arr) {
for (int i = 0; i < arr.size(); i++) {
// 迭代访问 arr[i]
}
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
def traverse(arr: List[int]):
for i in range(len(arr)):
# 迭代访问 arr[i]// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
func traverse(arr []int) {
for i := 0; i < len(arr); i++ {
// 迭代访问 arr[i]
}
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
/**
* @param {number[]} arr
* @return {void}
*/
var traverse = function(arr) {
for (var i = 0; i < arr.length; i++) {
// 迭代访问 arr[i]
}
}链表遍历框架,兼具迭代和递归结构:
/* 基本的单链表节点 */
class ListNode {
int val;
ListNode next;
}
void traverse(ListNode head) {
for (ListNode p = head; p != null; p = p.next) {
// 迭代访问 p.val
}
}
void traverse(ListNode head) {
// 递归访问 head.val
traverse(head.next);
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
/* 基本的单链表节点 */
class ListNode {
public:
int val;
ListNode* next;
};
void traverse(ListNode* head) {
for (ListNode* p = head; p != nullptr; p = p->next) {
// 迭代访问 p->val
}
}
void traverse(ListNode* head) {
// 递归访问 head->val
traverse(head->next);
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
# 基本的单链表节点
class ListNode:
def __init__(self, val):
self.val = val
self.next = None
def traverse(head: ListNode) -> None:
p = head
while p is not None:
# 迭代访问 p.val
p = p.next
def traverse(head: ListNode) -> None:
# 递归访问 head.val
traverse(head.next)// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 基本的单链表节点
type ListNode struct {
val int
next *ListNode
}
func traverse(head *ListNode) {
for p := head; p != nil; p = p.next {
// 迭代访问 p.val
}
}
func traverseRecursively(head *ListNode) {
// 递归访问 head.val
traverseRecursively(head.next)
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
/* 基本的单链表节点 */
class ListNode {
constructor(val) {
this.val = val;
this.next = null;
}
}
function traverse(head) {
for (var p = head; p != null; p = p.next) {
// 迭代访问 p.val
}
}
function traverse(head) {
// 递归访问 head.val
traverse(head.next);
}二叉树遍历框架,典型的非线性递归遍历结构:
/* 基本的二叉树节点 */
class TreeNode {
int val;
TreeNode left, right;
}
void traverse(TreeNode root) {
traverse(root.left);
traverse(root.right);
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
/* 基本的二叉树节点 */
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
};
void traverse(TreeNode* root) {
traverse(root->left);
traverse(root->right);
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
# 基本的二叉树节点
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
def traverse(root: TreeNode):
traverse(root.left)
traverse(root.right)// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 基本的二叉树节点
type TreeNode struct {
val int
left *TreeNode
right *TreeNode
}
// 后序遍历二叉树
func traverse(root *TreeNode) {
if root != nil {
traverse(root.left)
traverse(root.right)
}
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
/* 基本的二叉树节点 */
class TreeNode {
constructor(val) {
this.val = val;
this.left = null;
this.right = null;
}
}
var traverse = function(root) {
if (root === null) return;
traverse(root.left);
traverse(root.right);
};你看二叉树的递归遍历方式和链表的递归遍历方式,相似不?再看看二叉树结构和单链表结构,相似不?如果再多几条叉,N 叉树你会不会遍历?
二叉树框架可以扩展为 N 叉树的遍历框架:
/* 基本的 N 叉树节点 */
class TreeNode {
int val;
TreeNode[] children;
}
void traverse(TreeNode root) {
for (TreeNode child : root.children)
traverse(child);
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
/* 基本的 N 叉树节点 */
class TreeNode {
public:
int val;
vector<TreeNode*> children;
};
void traverse(TreeNode* root) {
for (TreeNode* child : root->children)
traverse(child);
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
# 基本的 N 叉树节点
class TreeNode:
val: int
children: List[TreeNode]
def traverse(root: TreeNode) -> None:
for child in root.children:
traverse(child)// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 基本的 N 叉树节点
type TreeNode struct {
val int
children []*TreeNode
}
func traverse(root *TreeNode) {
for _, child := range root.children {
traverse(child)
}
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
/* 基本的 N 叉树节点 */
var TreeNode = function(val, children) {
this.val = val;
this.children = children;
};
// 遍历 N 叉树
var traverse = function(root) {
for (var i = 0; i < root.children.length; i++) {
traverse(root.children[i]);
}
};N 叉树的遍历又可以扩展为图的遍历,因为图就是好几 N 叉棵树的结合体。你说图是可能出现环的?这个很好办,用个布尔数组 visited 做标记就行了,这里就不写代码了。
所谓框架,就是套路。不管增删查改,这些代码都是永远无法脱离的结构,你可以把这个结构作为大纲,根据具体问题在框架上添加代码就行了,下面会具体举例。
三、算法刷题指南
首先要明确的是,数据结构是工具,算法是通过合适的工具解决特定问题的方法。也就是说,学习算法之前,最起码得了解那些常用的数据结构,了解它们的特性和缺陷。
所以我建议的刷题顺序是:
1、先学习像数组、链表这种基本数据结构的常用算法,比如单链表翻转,前缀和数组,二分搜索等。
因为这些算法属于会者不难难者不会的类型,难度不大,学习它们不会花费太多时间。而且这些小而美的算法经常让你大呼精妙,能够有效培养你对算法的兴趣。
2、学会基础算法之后,不要急着上来就刷回溯算法、动态规划这类笔试常考题,而应该先刷二叉树,先刷二叉树,先刷二叉树,重要的事情说三遍。
这是我这刷题多年的亲身体会,下图是我刚开始学算法的提交截图:

公众号文章的阅读数据显示,大部分人对数据结构相关的算法文章不感兴趣,而是更关心动规回溯分治等等技巧。为什么要先刷二叉树呢,因为二叉树是最容易培养框架思维的,而且所有的递归算法技巧,本质上都是树的遍历问题。
刷二叉树看到题目没思路?根据很多读者的问题,其实大家不是没思路,只是没有理解我们说的「框架」是什么。
不要小看这几行破代码,几乎所有二叉树的题目都是一套这个框架就出来了:
void traverse(TreeNode root) {
// 前序位置
traverse(root.left);
// 中序位置
traverse(root.right);
// 后序位置
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
void traverse(TreeNode* root) {
// 前序位置
traverse(root->left);
// 中序位置
traverse(root->right);
// 后序位置
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
def traverse(root):
# 前序位置
traverse(root.left)
# 中序位置
traverse(root.right)
# 后序位置// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
func traverse(root *TreeNode) {
// 前序位置
traverse(root.left)
// 中序位置
traverse(root.right)
// 后序位置
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
var traverse = function(root) {
// 前序位置
traverse(root.left);
// 中序位置
traverse(root.right);
// 后序位置
}比如说我随便拿几道题的解法出来,不用管具体的代码逻辑,只要看看框架在其中是如何发挥作用的就行。
力扣第 124 题,难度困难,让你求二叉树中最大路径和,主要代码如下:
int res = Integer.MIN_VALUE;
int oneSideMax(TreeNode root) {
if (root == null) return 0;
int left = max(0, oneSideMax(root.left));
int right = max(0, oneSideMax(root.right));
// 后序位置
res = Math.max(res, left + right + root.val);
return Math.max(left, right) + root.val;
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
int res = INT_MIN;
int oneSideMax(TreeNode* root) {
if (root == nullptr) return 0;
int left = max(0, oneSideMax(root->left));
int right = max(0, oneSideMax(root->right));
// 后序位置
res = max(res, left + right + root->val);
return max(left, right) + root->val;
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
def oneSideMax(root: TreeNode) -> int:
if not root:
return 0
left = max(0, oneSideMax(root.left))
right = max(0, oneSideMax(root.right))
# 后序位置
global res
res = max(res, left + right + root.val)
return max(left, right) + root.val
res = -sys.maxsize - 1 # python equivalent of Integer.MIN_VALUE// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
import "math"
// Minimum value for an int32
// int32 的最小值
var res int = math.MinInt32
// 计算一侧节点的最大贡献值
func oneSideMax(root *TreeNode) int {
if root == nil {
return 0
}
// 左侧节点最大贡献值
left := int(math.Max(0, float64(oneSideMax(root.Left))))
// 右侧节点最大贡献值
right := int(math.Max(0, float64(oneSideMax(root.Right))))
// 计算经过当前根节点的路径和最大值
// 后序位置
res = int(math.Max(float64(res), float64(left + right + root.Val)))
// 当前路径上的最大权值和
return int(math.Max(float64(left), float64(right))) + root.Val
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
var res = Number.MIN_VALUE;
function oneSideMax(root) {
if (root == null) return 0;
var left = Math.max(0, oneSideMax(root.left));
var right = Math.max(0, oneSideMax(root.right));
// 后序位置
res = Math.max(res, left + right + root.val);
return Math.max(left, right) + root.val;
}注意递归函数的位置,这就是个后序遍历嘛,无非就是把 traverse 函数名字改成 oneSideMax 了。
力扣第 105 题,难度中等,让你根据前序遍历和中序遍历的结果还原一棵二叉树,很经典的问题吧,主要代码如下:
TreeNode build(int[] preorder, int preStart, int preEnd,
int[] inorder, int inStart, int inEnd) {
// 前序位置,寻找左右子树的索引
if (preStart > preEnd) {
return null;
}
int rootVal = preorder[preStart];
int index = 0;
for (int i = inStart; i <= inEnd; i++) {
if (inorder[i] == rootVal) {
index = i;
break;
}
}
int leftSize = index - inStart;
TreeNode root = new TreeNode(rootVal);
// 递归构造左右子树
root.left = build(preorder, preStart + 1, preStart + leftSize,
inorder, inStart, index - 1);
root.right = build(preorder, preStart + leftSize + 1, preEnd,
inorder, index + 1, inEnd);
return root;
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 前序遍历 preorder[preStart..preEnd],中序遍历 inorder[inStart..inEnd] 构造二叉树
TreeNode* build(vector<int>& preorder, int preStart, int preEnd,
vector<int>& inorder, int inStart, int inEnd) {
// 前序位置,寻找左右子树的索引
if (preStart > preEnd) {
return nullptr;
}
int rootVal = preorder[preStart];
int index = 0;
for (int i = inStart; i <= inEnd; i++) {
if (inorder[i] == rootVal) {
index = i;
break;
}
}
int leftSize = index - inStart;
TreeNode* root = new TreeNode(rootVal);
// 递归构造左右子树
root->left = build(preorder, preStart + 1, preStart + leftSize,
inorder, inStart, index - 1);
root->right = build(preorder, preStart + leftSize + 1, preEnd,
inorder, index + 1, inEnd);
return root;
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
def build(preorder: List[int], preStart: int, preEnd: int,
inorder: List[int], inStart: int, inEnd: int) -> TreeNode:
# 前序位置,寻找左右子树的索引
if preStart > preEnd:
return None
rootVal = preorder[preStart]
index = 0
for i in range(inStart, inEnd + 1):
if inorder[i] == rootVal:
index = i
break
leftSize = index - inStart
root = TreeNode(rootVal)
# 递归构造左右子树
root.left = build(preorder, preStart + 1, preStart + leftSize,
inorder, inStart, index - 1)
root.right = build(preorder, preStart + leftSize + 1, preEnd,
inorder, index + 1, inEnd)
return root// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
func build(preorder []int, preStart int, preEnd int,
inorder []int, inStart int, inEnd int) *TreeNode {
// 前序位置,寻找左右子树的索引
if preStart > preEnd {
return nil
}
rootVal := preorder[preStart]
index := 0
for i := inStart; i <= inEnd; i++ {
if inorder[i] == rootVal {
index = i
break
}
}
leftSize := index - inStart
root := &TreeNode{Val: rootVal}
// 递归构造左右子树
root.Left = build(preorder, preStart + 1, preStart + leftSize,
inorder, inStart, index - 1)
root.Right = build(preorder, preStart + leftSize + 1, preEnd,
inorder, index + 1, inEnd)
return root
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 前序位置,寻找左右子树的索引
var build = function(preorder, preStart, preEnd, inorder, inStart, inEnd) {
if (preStart > preEnd) {
return null;
}
var rootVal = preorder[preStart];
var index = 0;
for (var i = inStart; i <= inEnd; i++) {
if (inorder[i] == rootVal) {
index = i;
break;
}
}
var leftSize = index - inStart;
var root = new TreeNode(rootVal);
// 递归构造左右子树
root.left = build(preorder, preStart + 1, preStart + leftSize,
inorder, inStart, index - 1);
root.right = build(preorder, preStart + leftSize + 1, preEnd,
inorder, index + 1, inEnd);
return root;
};不要看这个函数的参数很多,只是为了控制数组索引而已。注意找递归函数 build 的位置,本质上该算法也就是一个前序遍历,因为它在前序遍历的位置加了一坨代码逻辑。
力扣第 230 题,难度中等,寻找二叉搜索树中的第 k 小的元素,主要代码如下:
int res = 0;
int rank = 0;
void traverse(TreeNode root, int k) {
if (root == null) {
return;
}
traverse(root.left, k);
/* 中序遍历代码位置 */
rank++;
if (k == rank) {
res = root.val;
return;
}
/*****************/
traverse(root.right, k);
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
int res = 0;
int rank = 0;
void traverse(TreeNode* root, int k) {
if (root == nullptr) {
return;
}
traverse(root->left, k);
/* 中序遍历代码位置 */
rank++;
if (k == rank) {
res = root->val;
return;
}
/*****************/
traverse(root->right, k);
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
res = 0
rank = 0
def traverse(root: TreeNode, k: int) -> None:
global res, rank
if root is None:
return
traverse(root.left, k)
# 中序遍历代码位置
rank += 1
if k == rank:
res = root.val
return
# 遍历右子树
traverse(root.right, k)// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
var res int
var rank int
func traverse(root *TreeNode, k int) {
if root == nil {
return
}
traverse(root.Left, k)
/* 中序遍历代码位置 */
rank++
if k == rank {
res = root.Val
return
}
/*****************/
traverse(root.Right, k)
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
var res = 0;
var rank = 0;
function traverse(root, k) {
if (root == null) {
return;
}
traverse(root.left, k);
/* 中序遍历代码位置 */
rank++;
if (k == rank) {
res = root.val;
return;
}
/*****************/
traverse(root.right, k);
}这不就是个中序遍历嘛,对于一棵 BST 中序遍历意味着什么,应该不需要解释了吧。
你看,二叉树的题目不过如此,只要把框架写出来,然后往相应的位置加代码就行了,这不就是思路吗。
对于一个理解二叉树的人来说,刷一道二叉树的题目花不了多长时间。那么如果你对刷题无从下手或者有畏惧心理,不妨从二叉树下手,前 10 道也许有点难受;结合框架再做 20 道,也许你就有点自己的理解了;刷完整个专题,再去做什么回溯动规分治专题,你就会发现只要涉及递归的问题,都是树的问题。
提示
本站的 二叉树专项练习章节 按照固定的公式和思维模式讲解了 150 道二叉树题目,可以手把手带你刷完二叉树分类的题目,迅速掌握递归思维。
再举例吧,说几道我们之前文章写过的问题。
动态规划详解说过凑零钱问题,暴力解法就是遍历一棵 N 叉树:
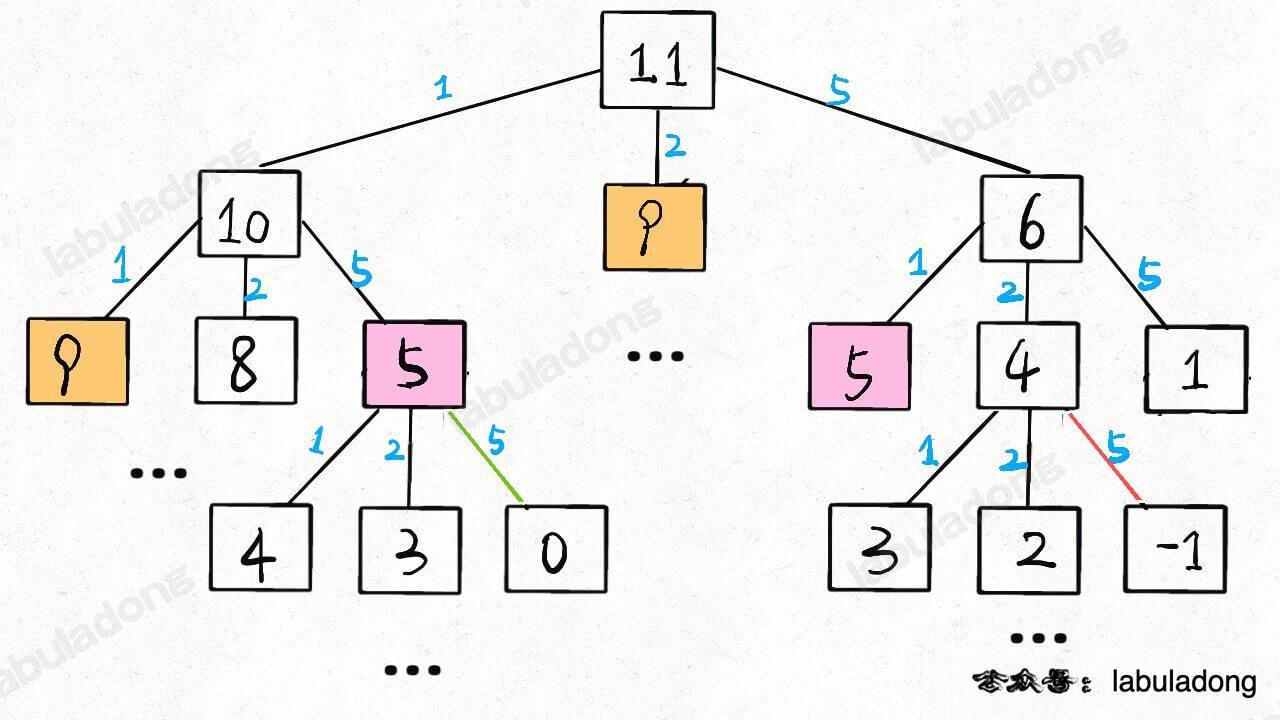
int dp(int[] coins, int amount) {
// base case
if (amount == 0) return 0;
if (amount < 0) return -1;
int res = Integer.MAX_VALUE;
for (int coin : coins) {
int subProblem = dp(coins, amount - coin);
// 子问题无解则跳过
if (subProblem == -1) continue;
// 在子问题中选择最优解,然后加一
res = Math.min(res, subProblem + 1);
}
return res == Integer.MAX_VALUE ? -1 : res;
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
int dp(vector<int>& coins, int amount) {
// base case
if (amount == 0) return 0;
if (amount < 0) return -1;
int res = INT_MAX;
for (int coin : coins) {
int subProblem = dp(coins, amount - coin);
// 子问题无解则跳过
if (subProblem == -1) continue;
// 在子问题中选择最优解,然后加一
res = min(res, subProblem + 1);
}
return res == INT_MAX ? -1 : res;
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
def dp(coins: List[int], amount: int) -> int:
# 基本情况
if amount == 0:
return 0
if amount < 0:
return -1
# 初始化结果为正无穷
res = float('inf')
# 遍历硬币数组并递归解决子问题
for coin in coins:
# 在子问题中选择最优解,然后加一
sub_problem = dp(coins, amount - coin)
# 子问题无解则跳过
if sub_problem == -1:
continue
res = min(res, sub_problem + 1)
# 如果结果仍然是正无穷则代表没有解决方案,返回-1
return -1 if res == float('inf') else res// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// dp函数定义,coins表示硬币数组,amount表示要凑出的金额数
func dp(coins []int, amount int) int {
// base case
if amount == 0 {
return 0
}
if amount < 0 {
return -1
}
// 初始化res为整型的最大值
res := math.MaxInt32
// 遍历当前所有硬币 coins,找到各位子问题的最优解
for _, coin := range coins {
subProblem := dp(coins, amount - coin)
// 子问题无解则跳过
if subProblem == -1 {
continue
}
// 在子问题中选择最优解,然后加一
res = min(res, subProblem + 1)
}
// 如果res没有更新,说明没有符合条件的方案,返回-1
if res == math.MaxInt32 {
return -1
}
// 返回结果
return res
}
// 比较两数大小,返回其中较小值
func min(a, b int) int {
if a < b {
return a
}
return b
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
var dp = function(coins, amount) {
// base case
if (amount == 0) return 0;
if (amount < 0) return -1;
var res = Number.MAX_SAFE_INTEGER;
for (var coin of coins) {
var subProblem = dp(coins, amount - coin);
// 子问题无解则跳过
if (subProblem == -1) continue;
// 在子问题中选择最优解,然后加一
res = Math.min(res, subProblem + 1);
}
return res == Number.MAX_SAFE_INTEGER ? -1 : res;
}这么多代码看不懂咋办?直接提取出框架,就能看出核心思路了:
// 注意:java 代码由 chatGPT🤖 根据我的 python 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 python 代码对比查看。
// 不过是一个 N 叉树的遍历问题而已
int dp(int amount) {
for (int coin : coins) {
dp(amount - coin);
}
}// 注意:cpp 代码由 chatGPT🤖 根据我的 python 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 python 代码对比查看。
int dp(int amount) {
// 不过是一个 N 叉树的遍历问题而已
for (int coin : coins) {
dp(amount - coin);
}
}# 不过是一个 N 叉树的遍历问题而已
int dp(int amount) {
for (int coin : coins) {
dp(amount - coin);
}
}// 注意:go 代码由 chatGPT🤖 根据我的 python 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 python 代码对比查看。
// 不过是一个 N 叉树的遍历问题而已
func dp(amount int) int {
for _, coin := range coins {
dp(amount - coin)
}
}// 注意:javascript 代码由 chatGPT🤖 根据我的 python 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 python 代码对比查看。
// 不过是一个 N 叉树的遍历问题而已
var dp = function (amount) {
for (var coin of coins) {
dp(amount - coin);
}
}其实很多动态规划问题就是在遍历一棵树,你如果对树的遍历操作烂熟于心,起码知道怎么把思路转化成代码,也知道如何提取别人解法的核心思路。
再看看回溯算法,后文 回溯算法详解 干脆直接说了,回溯算法就是个 N 叉树的前后序遍历问题,没有例外。
比如全排列问题吧,本质上全排列就是在遍历下面这棵树,到叶子节点的路径就是一个全排列:
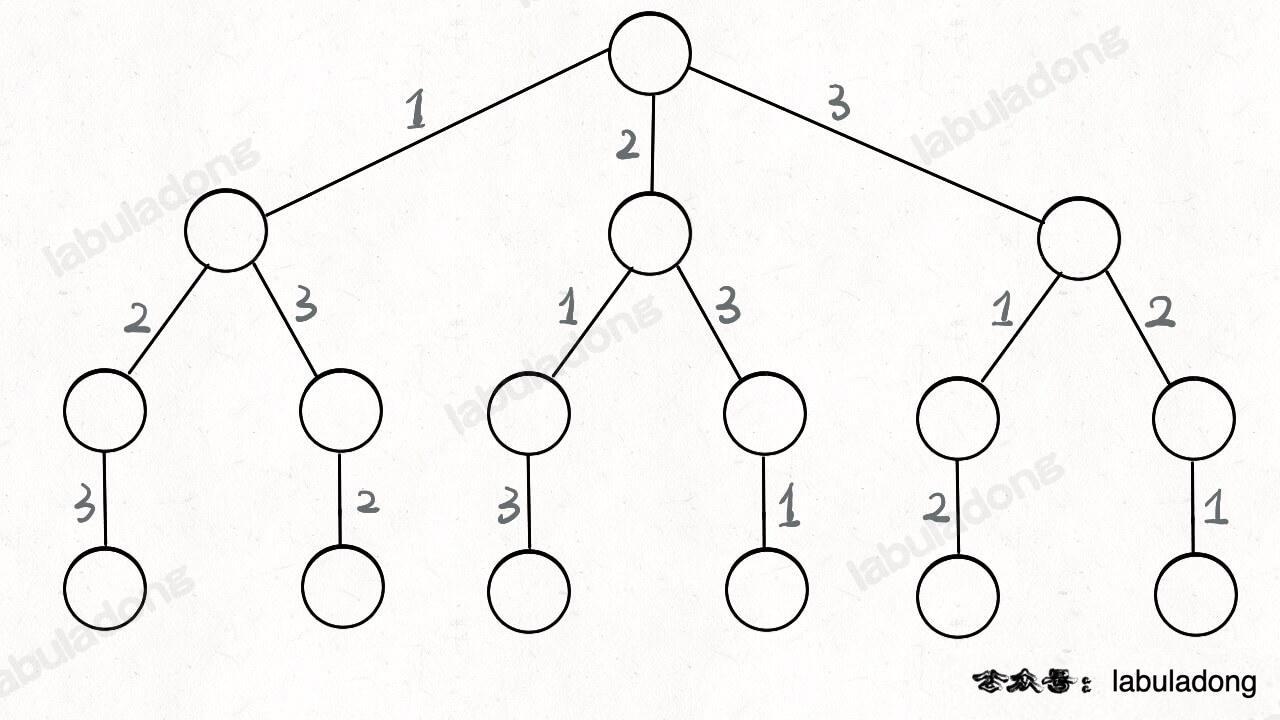
全排列算法的主要代码如下:
void backtrack(int[] nums, LinkedList<Integer> track) {
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
if (track.contains(nums[i]))
continue;
track.add(nums[i]);
// 进入下一层决策树
backtrack(nums, track);
track.removeLast();
}
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
void backtrack(vector<int>& nums, list<int>& track, vector<list<int>>& res) {
if (track.size() == nums.size()) {
res.push_back(list<int>(track.begin(), track.end()));
return;
}
for (int i = 0; i < nums.size(); i++) {
if (find(track.begin(), track.end(), nums[i]) != track.end())
continue;
track.push_back(nums[i]);
// 进入下一层决策树
backtrack(nums, track, res);
track.pop_back();
}
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
def backtrack(nums: List[int], track: List[int]) -> None:
# 如果走到了叶子结点,则将路径加入结果集
if len(track) == len(nums):
res.append(track[:])
return
for i in range(len(nums)):
# 如果数字已经在路径中出现过,则跳过
if nums[i] in track:
continue
track.append(nums[i])
# 进入下一层决策树
backtrack(nums, track)
track.pop()// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
func backtrack(nums []int, track []int, res *[][]int) {
// 判断是否达到决策树底层
if len(track) == len(nums) {
*res = append(*res, append([]int{}, track...)) // 将当前组合加入结果集中
return
}
for i := 0; i < len(nums); i++ {
if contains(track, nums[i]) { // 判重
continue
}
track = append(track, nums[i]) // 做选择
backtrack(nums, track, res) // 进入下一层决策树
track = track[:len(track)-1] // 撤销选择
}
}
func contains(track []int, val int) bool {
for _, v := range track {
if v == val {
return true
}
}
return false
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
var backtrack = function(nums, track) {
if (track.size() === nums.length) {
res.add(new LinkedList(track));
return;
}
for (var i = 0; i < nums.length; i++) {
if (track.contains(nums[i]))
continue;
track.add(nums[i]);
// 进入下一层决策树
backtrack(nums, track);
track.removeLast();
}
}看不懂?没关系,把其中的递归部分抽取出来:
/* 提取出 N 叉树遍历框架 */
void backtrack(int[] nums, LinkedList<Integer> track) {
for (int i = 0; i < nums.length; i++) {
backtrack(nums, track);
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 提取出 N 叉树遍历框架
void backtrack(vector<int>& nums, vector<int>& track) {
for (int i = 0; i < nums.size(); i++) {
backtrack(nums, track);
}
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
# 提取出 N 叉树遍历框架
def backtrack(nums: List[int], track: List[int]):
for i in range(len(nums)):
backtrack(nums, track)// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 提取出 N 叉树遍历框架
func backtrack(nums []int, track *list.List) {
for i := 0; i < len(nums); i++ {
backtrack(nums, track)
}
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
/* 提取出 N 叉树遍历框架 */
var backtrack = function(nums, track) {
for (var i = 0; i < nums.length; i++) {
backtrack(nums, track);
}
}N 叉树的遍历框架,找出来了吧?你说,树这种结构重不重要?
综上,对于畏惧算法的同学来说,可以先刷树的相关题目,试着从框架上看问题,而不要纠结于细节问题。
纠结细节问题,就比如纠结 i 到底应该加到 n 还是加到 n - 1,这个数组的大小到底应该开 n 还是 n + 1?
从框架上看问题,就是像我们这样基于框架进行抽取和扩展,既可以在看别人解法时快速理解核心逻辑,也有助于找到我们自己写解法时的思路方向。
当然,如果细节出错,你得不到正确的答案,但是只要有框架,你再错也错不到哪去,因为你的方向是对的。
但是,你要是心中没有框架,那么你根本无法解题,给了你答案,你也不会发现这就是个树的遍历问题。
这种思维是很重要的,动态规划详解 中总结的找状态转移方程的几步流程,有时候按照流程写出解法,可能自己都不知道为啥是对的,反正它就是对了。。。
这就是框架的力量,能够保证你在快睡着的时候,依然能写出正确的程序;就算你啥都不会,都能比别人高一个级别。
本文最后,总结一下吧:
数据结构的基本存储方式就是链式和顺序两种,基本操作就是增删查改,遍历方式无非迭代和递归。
学完基本算法之后,建议从「二叉树」系列问题开始刷,结合框架思维,把树结构理解到位,然后再去看回溯、动规、分治等算法专题,对思路的理解就会更加深刻。
引用本文的文章
引用本文的题目
安装 我的 Chrome 刷题插件 点开下列题目可直接查看解题思路:
| LeetCode | 力扣 |
|---|---|
| 341. Flatten Nested List Iterator | 341. 扁平化嵌套列表迭代器 |
| 589. N-ary Tree Preorder Traversal | 589. N 叉树的前序遍历 |
| 590. N-ary Tree Postorder Traversal | 590. N 叉树的后序遍历 |
《labuladong 的算法笔记》已经出版,关注公众号查看详情;后台回复「全家桶」可下载配套 PDF 和刷题全家桶:
