前文 哈希表核心原理 中我介绍了哈希表的核心原理和几个关键概念,其中提到了解决哈希冲突的方法主要有两种,分别是拉链法和开放寻址法(也常叫做线性探查法):
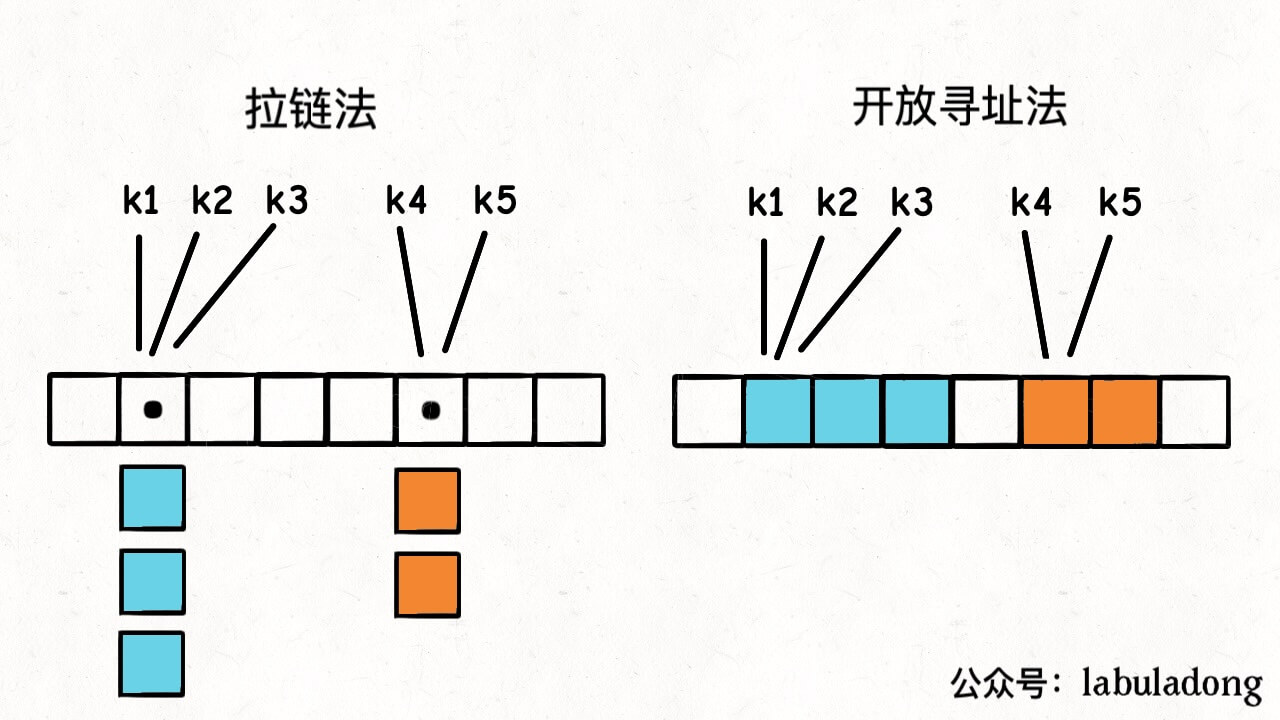
本文就来具体介绍一下拉链法的实现原理和代码。
首先,我会结合 可视化面板 用拉链法实现一个简化版的哈希表,带大家直观地理解拉链法是如何实现增删查改的 API 并解决哈希冲突的,最后再给出一个比较完善的 Java 代码实现。
拉链法的简化版实现
哈希表核心原理 已经介绍过哈希函数和 key 的类型的关系,其中 hash 函数的作用是在 O(1) 的时间把 key 转化成数组的索引,而 key 可以是任意不可变的类型。
但是这里为了方便诸位理解,我先做如下简化:
1、我们实现的哈希表只支持 key 类型为 int,value 类型为 int 的情况,如果 key 不存在,就返回 -1。
2、我们实现的 hash 函数就是简单地取模,即 hash(key) = key % table.length。这样也方便模拟出哈希冲突的情况,比如当 table.length = 10 时,hash(1) 和 hash(11) 的值都是 1。
3、底层的 table 数组的大小在创建哈希表时就固定,不考虑负载因子和动态扩缩容的问题。
这些简化能够帮助我们聚焦增删查改的核心逻辑,并且可以借助 可视化面板 辅助大家学习理解。
简化版代码
这里直接给出简化版的代码实现,你可以先看看,后面将通过可视化面板展示增删查改的过程:
import java.util.LinkedList;
// 用拉链法解决哈希冲突的简化实现
public class ExampleChainingHashMap {
// 链表节点,存储 key-value 对儿
// 注意这里必须存储同时存储 key 和 value
// 因为要通过 key 找到对应的 value
static class KVNode {
int key;
int value;
// 为了简化,我这里直接用标准库的 LinkedList 链表
// 所以这里就不添加 next 指针了
// 你当然可以给 KVNode 添加 next 指针,自己实现链表操作
public KVNode(int key, int value) {
this.key = key;
this.value = value;
}
}
// 底层 table 数组中的每个元素是一个链表
private LinkedList<KVNode>[] table;
public ExampleChainingHashMap(int capacity) {
table = new LinkedList[capacity];
}
private int hash(int key) {
return key % table.length;
}
// 查
public int get(int key) {
int index = hash(key);
if (table[index] == null) {
// 链表为空,说明 key 不存在
return -1;
}
LinkedList<KVNode> list = table[index];
// 遍历链表,尝试查找目标 key,返回对应的 value
for (KVNode node : list) {
if (node.key == key) {
return node.value;
}
}
// 链表中没有目标 key
return -1;
}
// 增/改
public void put(int key, int value) {
int index = hash(key);
if (table[index] == null) {
// 链表为空,新建一个链表,插入 key-value
table[index] = new LinkedList<>();
table[index].add(new KVNode(key, value));
return;
}
// 链表不为空,要遍历一遍看看 key 是否已经存在
// 如果存在,更新 value
// 如果不存在,插入新节点
LinkedList<KVNode> list = table[index];
for (KVNode node : list) {
if (node.key == key) {
// key 已经存在,更新 value
node.value = value;
return;
}
}
// 链表中没有目标 key,添加新节点
// 这里使用 addFirst 添加到链表头部或者 addLast 添加到链表尾部都可以
// 因为 Java LinkedList 的底层实现是双链表,头尾操作都是 O(1) 的
// https://labuladong.online/algo/data-structure-basic/linkedlist-implement/
list.addLast(new KVNode(key, value));
}
// 删
public void remove(int key) {
LinkedList<KVNode> list = table[hash(key)];
if (list == null) {
return;
}
// 如果 key 存在,则删除
// 这个 removeIf 方法是 Java LinkedList 的方法,可以删除满足条件的元素,时间复杂度 O(N)
list.removeIf(node -> node.key == key);
}
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
#include <vector>
#include <list>
#include <algorithm>
// 用拉链法解决哈希冲突的简化实现
class ExampleChainingHashMap {
// 链表节点,存储 key-value 对儿
// 注意这里必须存储同时存储 key 和 value
// 因为要通过 key 找到对应的 value
struct KVNode {
int key;
int value;
// 为了简化,我这里直接用标准库的 LinkedList 链表
// 所以这里就不添加 next 指针了
// 你当然可以给 KVNode 添加 next 指针,自己实现链表操作
KVNode(int key, int value) : key(key), value(value) {}
};
// 底层 table 数组中的每个元素是一个链表
std::vector<std::list<KVNode>> table;
public:
ExampleChainingHashMap(int capacity) : table(capacity) {}
int hash(int key) {
return key % table.size();
}
// 查
int get(int key) {
int index = hash(key);
if (table[index].empty()) {
// 链表为空,说明 key 不存在
return -1;
}
for (const auto& node : table[index]) {
if (node.key == key) {
return node.value;
}
}
// 链表中没有目标 key
return -1;
}
// 增/改
void put(int key, int value) {
int index = hash(key);
if (table[index].empty()) {
// 链表为空,新建一个链表,插入 key-value
table[index].push_back(KVNode(key, value));
return;
}
// 链表不为空,要遍历一遍看看 key 是否已经存在
// 如果存在,更新 value
// 如果不存在,插入新节点
for (auto& node : table[index]) {
if (node.key == key) {
// key 已经存在,更新 value
node.value = value;
return;
}
}
// 链表中没有目标 key,添加新节点
// 这里使用 addFirst 添加到链表头部或者 addLast 添加到链表尾部都可以
// 因为 Java LinkedList 的底层实现是双链表,头尾操作都是 O(1) 的
// https://labuladong.online/algo/data-structure-basic/linkedlist-implement/
table[index].push_back(KVNode(key, value));
}
// 删
void remove(int key) {
auto& list = table[hash(key)];
if (list.empty()) {
return;
}
// 如果 key 存在,则删除
// 这个 removeIf 方法是 Java LinkedList 的方法,可以删除满足条件的元素,时间复杂度 O(N)
list.remove_if([key](KVNode& node) { return node.key == key; });
}
};# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
class KVNode:
# 链表节点,存储 key-value 对儿
def __init__(self, key, value):
self.key = key
self.value = value
class ExampleChainingHashMap:
def __init__(self, capacity):
# 底层 table 数组中的每个元素是一个链表
self.table = [None] * capacity
def hash(self, key):
return key % len(self.table)
def get(self, key):
# 查
index = self.hash(key)
if self.table[index] is None:
# 链表为空,说明 key 不存在
return -1
list = self.table[index]
# 遍历链表,尝试查找目标 key,返回对应的 value
for node in list:
if node.key == key:
return node.value
# 链表中没有目标 key
return -1
def put(self, key, value):
# 增/改
index = self.hash(key)
if self.table[index] is None:
# 链表为空,新建一个链表,插入 key-value
self.table[index] = []
self.table[index].append(KVNode(key, value))
return
list = self.table[index]
for node in list:
if node.key == key:
# key 已经存在,更新 value
node.value = value
return
# 链表中没有目标 key,添加新节点
list.append(KVNode(key, value))
def remove(self, key):
# 删
list = self.table[self.hash(key)]
if list is None:
return
# 如果 key 存在,则删除
list[:] = [node for node in list if node.key != key]// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
import "container/list"
// 用拉链法解决哈希冲突的简化实现
type KVNode struct {
key int
value int
}
// 底层 table 数组中的每个元素是一个链表
type ExampleChainingHashMap struct {
table []*list.List
}
// 注意这里必须存储同时存储 key 和 value
// 因为要通过 key 找到对应的 value
func NewExampleChainingHashMap(capacity int) ExampleChainingHashMap {
return ExampleChainingHashMap{
table: make([]*list.List, capacity),
}
}
func (h *ExampleChainingHashMap) hash(key int) int {
return key % len(h.table)
}
// 查
func (h *ExampleChainingHashMap) Get(key int) (int, bool) {
index := h.hash(key)
if h.table[index] == nil {
// 链表为空,说明 key 不存在
return -1, false
}
for e := h.table[index].Front(); e != nil; e = e.Next() {
node := e.Value.(KVNode)
if node.key == key {
return node.value, true
}
}
// 链表中没有目标 key
return -1, false
}
// 增/改
func (h *ExampleChainingHashMap) Put(key int, value int) {
index := h.hash(key)
if h.table[index] == nil {
// 链表为空,新建一个链表,插入 key-value
h.table[index] = list.New()
h.table[index].PushBack(KVNode{key, value})
return
}
for e := h.table[index].Front(); e != nil; e = e.Next() {
node := e.Value.(KVNode)
if node.key == key {
// key 已经存在,更新 value
node.value = value
return
}
}
// 链表中没有目标 key,添加新节点
// 这里使用 addFirst 添加到链表头部或者 addLast 添加到链表尾部都可以
// 因为 Java LinkedList 的底层实现是双链表,头尾操作都是 O(1) 的
h.table[index].PushBack(KVNode{key, value})
}
// 删
func (h *ExampleChainingHashMap) Remove(key int) {
index := h.hash(key)
if h.table[index] == nil {
return
}
for e := h.table[index].Front(); e != nil; e = e.Next() {
node := e.Value.(KVNode)
if node.key == key {
// 如果 key 存在,则删除
h.table[index].Remove(e)
return
}
}
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 用拉链法解决哈希冲突的简化实现
var ExampleChainingHashMap = function(capacity) {
// 链表节点,存储 key-value 对儿
// 注意这里必须存储同时存储 key 和 value
// 因为要通过 key 找到对应的 value
var KVNode = function(key, value) {
this.key = key;
this.value = value;
};
// 底层 table 数组中的每个元素是一个链表
this.table = new Array(capacity);
this.hash = function(key) {
return key % this.table.length;
};
// 查
this.get = function(key) {
var index = this.hash(key);
if (this.table[index] == null) {
// 链表为空,说明 key 不存在
return -1;
}
var list = this.table[index];
// 遍历链表,尝试查找目标 key,返回对应的 value
for (var i = 0; i < list.length; i++) {
if (list[i].key == key) {
return list[i].value;
}
}
// 链表中没有目标 key
return -1;
};
// 增/改
this.put = function(key, value) {
var index = this.hash(key);
if (this.table[index] == null) {
// 链表为空,新建一个链表,插入 key-value
this.table[index] = [];
this.table[index].push(new KVNode(key, value));
return;
}
// 链表不为空,要遍历一遍看看 key 是否已经存在
// 如果存在,更新 value
// 如果不存在,插入新节点
var list = this.table[index];
for (var i = 0; i < list.length; i++) {
if (list[i].key == key) {
// key 已经存在,更新 value
list[i].value = value;
return;
}
}
// 链表中没有目标 key,添加新节点
// 因为 JavaScript Array 的 push 方法时间复杂度是 O(1)
list.push(new KVNode(key, value));
};
// 删
this.remove = function(key) {
var list = this.table[this.hash(key)];
if (list == null) {
return;
}
// 如果 key 存在,则删除,时间复杂度 O(N)
for (var i = 0; i < list.length; i++) {
if (list[i].key == key) {
list.splice(i, 1);
return;
}
}
}
}可视化面板展示增删查改过程
提示
我用可视化面板内置的单链表节点类 ListNode 类来存储键值对。由于 ListNode 类只有一个 val 字段,所以我把键和值组装成 key:value 这样的字符串存储在 val 字段中,方便可视化展示。
直接点击代码就可以跳转执行到对应位置。直接点击 map.put(...) 这些方法调用,就可以直观地看到每个方法调用的效果;点击上一步 < 和下一步 > 按钮可以逐步查看增删查改的具体过程。
你也可以点击「编辑」按钮修改代码,尝试不同的输入。
完整代码实现
有了上面的铺垫,我们现在来看一个比较完善的 Java 代码实现,主要新增了以下几个功能:
1、使用了泛型,可以存储任意类型的 key 和 value。
2、底层的 table 数组会根据负载因子动态扩缩容。
3、使用了 哈希表基础 中提到的 hash 函数,利用 key 的 hashCode() 方法和 table.length 来计算哈希值。
4、实现了 keys() 方法,可以返回哈希表中所有的 key。
为了方便,我直接使用 Java 标准库的 LinkedList 作为链表,这样就不用自己手动处理增删链表节点的操作了。当然如果你愿意的话,可以参照前文 单/双链表代码实现 自己编写操作 KVNode 的逻辑。
具体需要注意的细节我都写在了代码注释中,直接看代码吧:
import java.util.LinkedList;
import java.util.List;
public class MyChainingHashMap<K, V> {
// 拉链法使用的单链表节点,存储 key-value 对
private static class KVNode<K, V> {
K key;
V value;
// 因为我们使用了内置的 LinkedList 类,所以不用 next 指针
// 不用我们自己实现链表的逻辑
KVNode(K key, V val) {
this.key = key;
this.value = val;
}
}
// 哈希表的底层数组,每个数组元素是一个链表,链表中每个节点是 KVNode 存储键值对
private LinkedList<KVNode<K, V>>[] table;
// 哈希表中存入的键值对个数
private int size;
// 底层数组的初始容量
private static final int INIT_CAP = 4;
public MyChainingHashMap() {
this(INIT_CAP);
}
public MyChainingHashMap(int initCapacity) {
size = 0;
// 保证底层数组的容量至少为 1,因为 hash 函数中有求余运算,避免出现除以 0 的情况
initCapacity = Math.max(initCapacity, 1);
// 初始化哈希表
table = (LinkedList<KVNode<K, V>>[]) new LinkedList[initCapacity];
for (int i = 0; i < table.length; i++) {
table[i] = new LinkedList<>();
}
}
/***** 增/改 *****/
// 添加 key -> val 键值对
// 如果键 key 已存在,则将值修改为 val
public void put(K key, V val) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
LinkedList<KVNode<K, V>> list = table[hash(key)];
// 如果 key 之前存在,则修改对应的 val
for (KVNode<K, V> node : list) {
if (node.key.equals(key)) {
node.value = val;
return;
}
}
// 如果 key 之前不存在,则插入,size 增加
list.add(new KVNode<>(key, val));
size++;
// 如果元素数量超过了负载因子,进行扩容
if (size >= table.length * 0.75) {
resize(table.length * 2);
}
}
/***** 删 *****/
// 删除 key 和对应的 val
public void remove(K key) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
LinkedList<KVNode<K, V>> list = table[hash(key)];
// 如果 key 存在,则删除,size 减少
for (KVNode<K, V> node : list) {
if (node.key.equals(key)) {
list.remove(node);
size--;
// 缩容,当负载因子小于 0.125 时,缩容
if (size <= table.length / 8) {
resize(table.length / 4);
}
return;
}
}
}
/***** 查 *****/
// 返回 key 对应的 val,如果 key 不存在,则返回 null
public V get(K key) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
LinkedList<KVNode<K, V>> list = table[hash(key)];
for (KVNode<K, V> node : list) {
if (node.key.equals(key)) {
return node.value;
}
}
return null;
}
// 返回所有 key
public List<K> keys() {
List<K> keys = new LinkedList<>();
for (LinkedList<KVNode<K, V>> list : table) {
for (KVNode<K, V> node : list) {
keys.add(node.key);
}
}
return keys;
}
/***** 其他工具函数 *****/
public int size() {
return size;
}
// 哈希函数,将键映射到 table 的索引
private int hash(K key) {
return (key.hashCode() & 0x7fffffff) % table.length;
}
private void resize(int newCap) {
// 构造一个新的 HashMap
// 避免 newCap 为 0,造成求模运算产生除以 0 的异常
newCap = Math.max(newCap, 1);
MyChainingHashMap<K, V> newMap = new MyChainingHashMap<>(newCap);
// 穷举当前 HashMap 中的所有键值对
for (LinkedList<KVNode<K, V>> list : table) {
for (KVNode<K, V> node : list) {
// 将键值对转移到新的 HashMap 中
newMap.put(node.key, node.value);
}
}
// 将当前 HashMap 的底层 table 换掉
this.table = newMap.table;
}
public static void main(String[] args) {
MyChainingHashMap<Integer, Integer> map = new MyChainingHashMap<>();
map.put(1, 1);
map.put(2, 2);
map.put(3, 3);
System.out.println(map.get(1)); // 1
System.out.println(map.get(2)); // 2
map.put(1, 100);
System.out.println(map.get(1)); // 100
map.remove(2);
System.out.println(map.get(2)); // null
System.out.println(map.keys()); // [1, 3](顺序可能不同)
map.remove(1);
map.remove(2);
map.remove(3);
System.out.println(map.get(1)); // null
}
}