前文 二叉堆的原理 介绍了二叉堆的基本性质、API 和常见应用。本文将结合 可视化面板 手把手带你实现一个优先级队列。
我们先实现一个简化版的优先级队列,用来帮你理解二叉堆的核心操作 sink 和 swim。最后我再用给出一个比较完整的代码实现。
简化版优先级队列
我们实现的这个简化版优先级队列有如下限制:
1、不支持泛型,仅支持存储整数类型的元素。
2、不考虑扩容的问题,队列的容量在创建时固定,假设插入的元素数量不会超过这个容量。
3、底层仅实现一个小顶堆(即根节点是整个堆中的最小值),不支持自定义比较器。
基于上面这些限制,这个简化版优先级队列的 API 如下:
class SimpleMinPQ {
// 创建一个容量为 capacity 的优先级队列
public SimpleMinPQ(int capacity);
// 返回队列中的元素个数
public int size();
// 向队列中插入一个元素
public void push(int x);
// 返回队列中的最小元素(堆顶元素)
public int peek();
// 删除并返回队列中的最小元素(堆顶元素)
public int pop();
}使用方法如下:
SimpleMinPQ pq = new SimpleMinPQ(10);
pq.push(3);
pq.push(4);
pq.push(1);
pq.push(2);
System.out.println(pq.pop()); // 1
System.out.println(pq.pop()); // 2
System.out.println(pq.pop()); // 3
System.out.println(pq.pop()); // 4难点分析
在前文 二叉堆的原理 中你应该也感觉到了,二叉堆的难点在于 你在插入或删除元素时,还要保持堆的性质。
具体来说,看下面这个可视化面板,我在这个小顶堆中调用 push 方法插入元素 4,然后再调用 pop 方法删除堆顶元素 0。
实操
请你先点击 let minHeap 这部分代码,让最小堆以及初始元素构造出来。注意看每个二叉树节点的值都比它的两个子树上的节点的值小,满足小顶堆的性质。
然后点击 push(4) 那行代码,可以看到这个新元素 4 被插入到了原先 6 的位置,而 6 被下沉为 4 的子节点,这样依然保持了小顶堆的性质。如果你直接把 4 放到树的最下层的话,比如作为 6 的子节点,就不满足小顶堆的性质了。
最后点击 pop() 那行代码,可以看到堆顶元素 0 被删除,元素 1 取代了 0 的位置作为新的堆顶元素,而 6 被从最左侧移动元素 1 原先的位置。这样依然保持了小顶堆的性质。
你可以自己修改代码并运行,看看右侧二叉堆结构的变化,无论怎么插入或删除元素,这个小顶堆都能保持其性质。咋做到的?下面来讲。
增:push 方法插入元素
核心步骤
以小顶堆为例,向小顶堆中插入新元素遵循两个步骤:
1、先把新元素追加到二叉树底层的最右侧,保持完全二叉树的结构。此时该元素的父节点可能比它大,不满足小顶堆的性质。
2、为了恢复小顶堆的性质,需要将这个新元素不断上浮(swim),直到它的父节点比它小为止,或者到达根节点。此时整个二叉树就满足小顶堆的性质了。
我用可视化面面板具体展示一下上述操作。
在可视化面板中,二叉堆中的每个节点就是一个经过改造的二叉树节点,除了包含 left, right, val 这些属性外,还有一个 parent 属性,指向该节点的父节点:
class HeapNode {
constructor(val) {
this.val = val;
this.left = null;
this.right = null;
this.parent = null;
}
}我提供了一个 Heap._makeNode(val) 方法来创建一个 HeapNode 节点。
那么我们就可以自己尝试实现 push 方法的大致流程了,看我的实现:
这个可视化面板应该把上述两个步骤展示的很清晰了,最终二叉堆的性质恢复了,你也可以自己尝试修改代码玩一玩。
删:pop 方法删除元素
核心步骤
以小顶堆为例,删除小顶堆的堆顶元素遵循两个步骤:
1、先把堆顶元素删除,把二叉树底层的最右侧元素摘除并移动到堆顶,保持完全二叉树的结构。此时堆顶元素可能比它的子节点大,不满足小顶堆的性质。
2、为了恢复小顶堆的性质,需要将这个新的堆顶元素不断下沉(sink),直到它的子节点比它小为止,或者到达叶子节点。此时整个二叉树就满足小顶堆的性质了。
我用可视化面面板具体展示一下上述操作,看我的实现:
这个可视化面板应该把上述两个步骤展示的很清晰了,最终二叉堆的性质恢复了,你也可以自己尝试修改代码玩一玩。
查:peek 方法查看堆顶元素
这个很简单吧,直接返回根节点的值就行了,我就不多说了。
在数组上模拟二叉树
在之前的所有内容中,我都把二叉堆作为一种二叉树来讲解,而且可视化面板中也是通过操作 HeapNode 节点的方式来展示的。但实际上,我们在代码实现的时候,不会用类似 HeapNode 的节点类来实现,而是用数组来模拟二叉树结构。
用数组模拟二叉树的原因
第一个原因是前面介绍 数组 和 链表 时说到的,链表节点需要一个额外的指针存储相邻节点的地址,所以相对数组,链表的内存消耗会大一些。我们这里的 HeapNode 类也是链式存储的例子,和链表节点类似,需要额外的指针存储父节点和子节点的地址。
第二个原因,也是最主要的原因,是时间复杂度的问题。仔细想一下前面我给你展示的 push 和 pop 方法的操作过程,它们的第一步是什么?是不是要找到二叉树最底层的最右侧元素?
因为上面举的场景是我们自己构造的,可以直接用操作 left, right 指针的方式把目标节点拿到。但你想想,正常情况下你如何拿到二叉树的底层最右侧节点?你需要层序遍历或递归遍历二叉树,时间复杂度是 O(N),进而导致 push 和 pop 方法的时间复杂度退化到 O(N),这显然是不可接受的。
如果用数组来模拟二叉树,就可以完美解决这个问题,在 O(1) 时间内找到二叉树的底层最右侧节点。
完全二叉树是关键
想要用数组模拟二叉树,前提是这个二叉树必须是完全二叉树。
我在 二叉树基础 中介绍过完全二叉树,就是除了最后一层,其他层的节点都是满的,最后一层的节点都靠左排列。
由于完全二叉树上的元素都是紧凑排列的,我们可以用数组来存储,看这幅图就明白了:
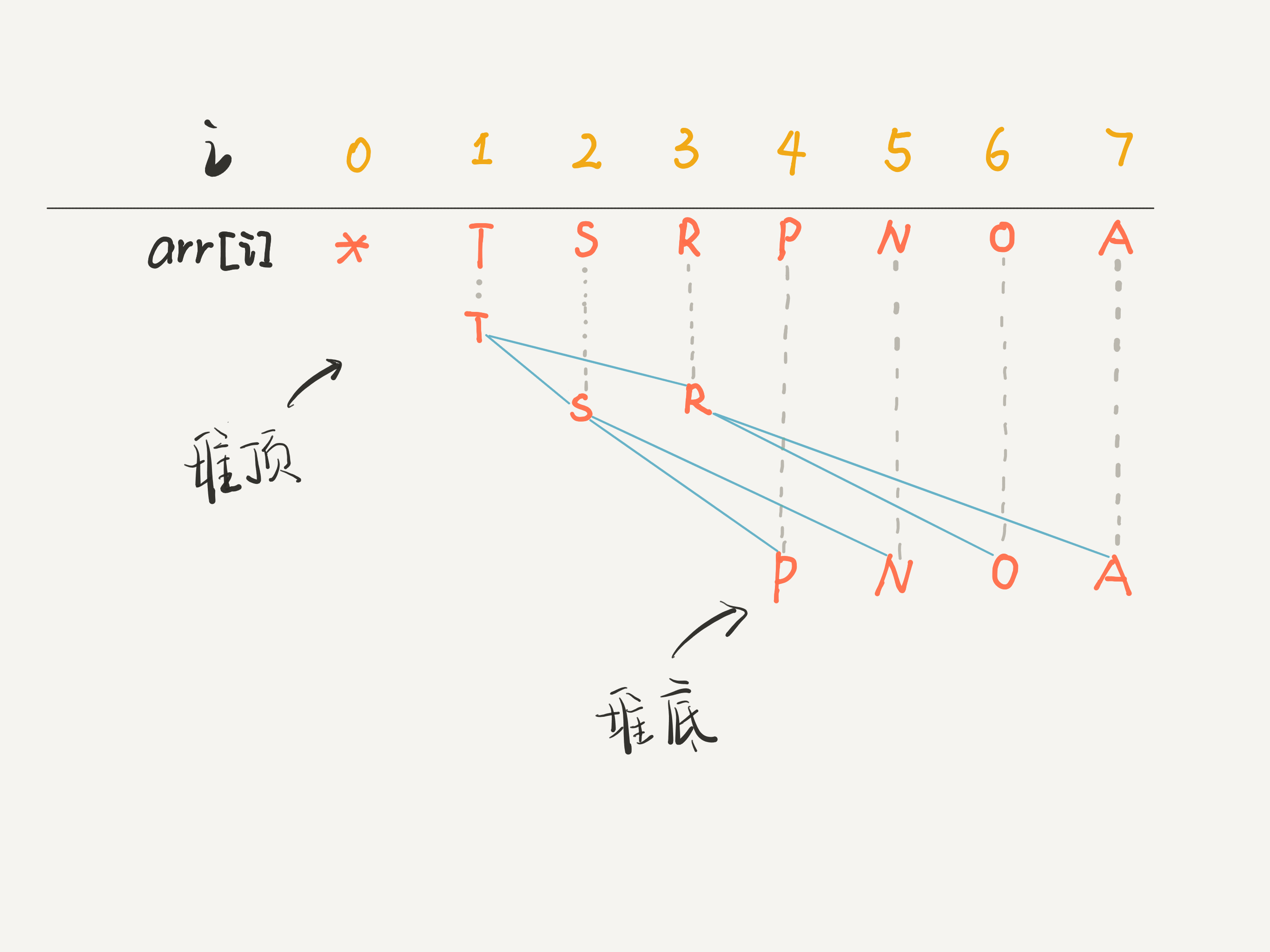
在这个数组中,索引 0 空着不用,就可以根据任意节点的索引计算出父节点或左右子节点的索引:
// 父节点的索引
int parent(int node) {
return node / 2;
}
// 左子节点的索引
int left(int node) {
return node * 2;
}
// 右子节点的索引
int right(int node) {
return node * 2 + 1;
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 父节点的索引
int parent(int node) {
return node / 2;
}
// 左子节点的索引
int left(int node) {
return node * 2;
}
// 右子节点的索引
int right(int node) {
return node * 2 + 1;
}# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
# 父节点的索引
def parent(node: int) -> int:
return node // 2
# 左子节点的索引
def left(node: int) -> int:
return node * 2
# 右子节点的索引
def right(node: int) -> int:
return node * 2 + 1// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 父节点的索引
func parent(node int) int {
return node / 2
}
// 左子节点的索引
func left(node int) int {
return node * 2
}
// 右子节点的索引
func right(node int) int {
return node * 2 + 1
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
// 父节点的索引
var parent = function(node) {
return Math.floor(node / 2);
}
// 左子节点的索引
var left = function(node) {
return node * 2;
}
// 右子节点的索引
var right = function(node) {
return node * 2 + 1;
}我们直接在数组的末尾追加元素,就相当于在完全二叉树的最后一层从左到右依次填充元素;数组中最后一个元素,就是完全二叉树的底层最右侧的元素,完美契合我们实现二叉堆的场景。
有了上面的铺垫,代码实现就呼之欲出了。
代码实现
下面是一个简化版的小顶堆优先级队列核心逻辑的实现,没有特别出列边界情况,供你参考:
class SimpleMinPQ {
private final int[] heap;
private int size;
public SimpleMinPQ(int capacity) {
// 索引 0 空着不用,所以多分配一个空间
heap = new int[capacity + 1];
size = 0;
}
public int size() {
return size;
}
// 父节点的索引
int parent(int node) {
return node / 2;
}
// 左子节点的索引
int left(int node) {
return node * 2;
}
// 右子节点的索引
int right(int node) {
return node * 2 + 1;
}
// 交换数组的两个元素
private void swap(int i, int j) {
int temp = heap[i];
heap[i] = heap[j];
heap[j] = temp;
}
// 查,返回堆顶元素,时间复杂度 O(1)
public int peek() {
// 索引 0 空着不用,所以堆顶元素是索引 1
return heap[1];
}
// 增,向堆中插入一个元素,时间复杂度 O(logN)
public void push(int x) {
// 把新元素放到最后
heap[++size] = x;
// 然后上浮到正确位置
swim(size);
}
// 删,删除堆顶元素,时间复杂度 O(logN)
public int pop() {
int res = heap[1];
// 把堆底元素放到堆顶
heap[1] = heap[size--];
// 然后下沉到正确位置
sink(1);
return res;
}
// 上浮操作,时间复杂度是树高 O(logN)
private void swim(int x) {
while (x > 1 && heap[parent(x)] > heap[x]) {
swap(parent(x), x);
x = parent(x);
}
}
// 下沉操作,时间复杂度是树高 O(logN)
private void sink(int x) {
while (left(x) <= size || right(x) <= size) {
int min = x;
if (left(x) <= size && heap[left(x)] < heap[min]) {
min = left(x);
}
if (right(x) <= size && heap[right(x)] < heap[min]) {
min = right(x);
}
if (min == x) {
break;
}
swap(x, min);
x = min;
}
}
}// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
class SimpleMinPQ {
private:
int* heap;
int size;
public:
SimpleMinPQ(int capacity) {
// 索引 0 空着不用,所以多分配一个空间
heap = new int[capacity + 1];
size = 0;
}
int sizeFunc() {
return size;
}
// 父节点的索引
int parent(int node) {
return node / 2;
}
// 左子节点的索引
int left(int node) {
return node * 2;
}
// 右子节点的索引
int right(int node) {
return node * 2 + 1;
}
// 交换数组的两个元素
void swap(int i, int j) {
int temp = heap[i];
heap[i] = heap[j];
heap[j] = temp;
}
// 查,返回堆顶元素,时间复杂度 O(1)
int peek() {
// 索引 0 空着不用,所以堆顶元素是索引 1
return heap[1];
}
// 增,向堆中插入一个元素,时间复杂度 O(logN)
void push(int x) {
// 把新元素放到最后
heap[++size] = x;
// 然后上浮到正确位置
swim(size);
}
// 删,删除堆顶元素,时间复杂度 O(logN)
virtual int pop() {
int res = heap[1];
// 把堆底元素放到堆顶
heap[1] = heap[size--];
// 然后下沉到正确位置
sink(1);
return res;
}
// 上浮操作,时间复杂度是树高 O(logN)
void swim(int x) {
while (x > 1 && heap[parent(x)] > heap[x]) {
swap(parent(x), x);
x = parent(x);
}
}
// 下沉操作,时间复杂度是树高 O(logN)
void sink(int x) {
while (left(x) <= size || right(x) <= size) {
int min = x;
if (left(x) <= size && heap[left(x)] < heap[min]) {
min = left(x);
}
if (right(x) <= size && heap[right(x)] < heap[min]) {
min = right(x);
}
if (min == x) {
break;
}
swap(x, min);
x = min;
}
}
};# 注意:python 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
# 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
class SimpleMinPQ:
def __init__(self, capacity):
# 索引 0 空着不用,所以多分配一个空间
self.heap = [0] * (capacity + 1)
self.size = 0
def size_s(self):
return self.size
# 父节点的索引
def parent(self, node):
return node // 2
# 左子节点的索引
def left(self, node):
return node * 2
# 右子节点的索引
def right(self, node):
return node * 2 + 1
# 交换数组的两个元素
def swap(self, i, j):
temp = self.heap[i]
self.heap[i] = self.heap[j]
self.heap[j] = temp
# 查,返回堆顶元素,时间复杂度 O(1)
def peek(self):
# 索引 0 空着不用,所以堆顶元素是索引 1
return self.heap[1]
# 增,向堆中插入一个元素,时间复杂度 O(logN)
def push(self, x):
# 把新元素放到最后
self.size += 1
self.heap[self.size] = x
# 然后上浮到正确位置
self.swim(self.size)
# 删,删除堆顶元素,时间复杂度 O(logN)
def pop(self):
res = self.heap[1]
# 把堆底元素放到堆顶
self.heap[1] = self.heap[self.size]
self.size -= 1
# 然后下沉到正确位置
self.sink(1)
return res
# 上浮操作,时间复杂度是树高 O(logN)
def swim(self, x):
while x > 1 and self.heap[self.parent(x)] > self.heap[x]:
self.swap(self.parent(x), x)
x = self.parent(x)
# 下沉操作,时间复杂度是树高 O(logN)
def sink(self, x):
while self.left(x) <= self.size or self.right(x) <= self.size:
min_val = x
# 如果左子节点存在(没有越界)且左子节点的值小于父节点,那么最小的值就是左子节点
if self.left(x) <= self.size and self.heap[self.left(x)] < self.heap[min_val]:
min_val = self.left(x)
# 如果右子节点存在(没有越界)且右子节点的值小于“目前已知的最小值”(父节点 or 左子节点),那么最小的值就是右子节点
if self.right(x) <= self.size and self.heap[self.right(x)] < self.heap[min_val]:
min_val = self.right(x)
# 如果 min == x 说明 x 确实是最小的,不需要做switch
if min_val == x:
break
self.swap(x, min_val)
x = min_val// 注意:go 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
type SimpleMinPQ struct {
heap []int
size int
}
func NewSimpleMinPQ(capacity int) *SimpleMinPQ {
// 索引 0 空着不用,所以多分配一个空间
return &SimpleMinPQ{
heap: make([]int, capacity+1),
size: 0,
}
}
func (pq *SimpleMinPQ) Size() int {
return pq.size
}
func parent(node int) int {
return node / 2
}
func left(node int) int {
return node * 2
}
func right(node int) int {
return node * 2 + 1
}
func (pq *SimpleMinPQ) swap(i, j int) {
temp := pq.heap[i]
pq.heap[i] = pq.heap[j]
pq.heap[j] = temp
}
func (pq *SimpleMinPQ) Peek() int {
// 索引 0 空着不用,所以堆顶元素是索引 1
return pq.heap[1]
}
func (pq *SimpleMinPQ) Push(x int) {
// 把新元素放到最后
pq.size++
pq.heap[pq.size] = x
// 然后上浮到正确位置
pq.swim(pq.size)
}
func (pq *SimpleMinPQ) Pop() int {
res := pq.heap[1]
// 把堆底元素放到堆顶
pq.heap[1] = pq.heap[pq.size]
pq.size--
// 然后下沉到正确位置
pq.sink(1)
return res
}
func (pq *SimpleMinPQ) swim(x int) {
for x > 1 && pq.heap[parent(x)] > pq.heap[x] {
pq.swap(parent(x), x)
x = parent(x)
}
}
func (pq *SimpleMinPQ) sink(x int) {
for left(x) <= pq.size || right(x) <= pq.size {
min := x
if left(x) <= pq.size && pq.heap[left(x)] < pq.heap[min] {
min = left(x)
}
if right(x) <= pq.size && pq.heap[right(x)] < pq.heap[min] {
min = right(x)
}
if min == x {
break
}
pq.swap(x, min)
x = min
}
}// 注意:javascript 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
var SimpleMinPQ = function(capacity) {
// 索引 0 空着不用,所以多分配一个空间
this.heap = new Array(capacity + 1);
this.size = 0;
}
SimpleMinPQ.prototype.size = function() {
return this.size;
}
// 父节点的索引
SimpleMinPQ.prototype.parent = function(node) {
return Math.floor(node / 2);
}
// 左子节点的索引
SimpleMinPQ.prototype.left = function(node) {
return node * 2;
}
// 右子节点的索引
SimpleMinPQ.prototype.right = function(node) {
return node * 2 + 1;
}
// 交换数组的两个元素
SimpleMinPQ.prototype.swap = function(i, j) {
var temp = this.heap[i];
this.heap[i] = this.heap[j];
this.heap[j] = temp;
}
// 查,返回堆顶元素,时间复杂度 O(1)
SimpleMinPQ.prototype.peek = function() {
// 索引 0 空着不用,所以堆顶元素是索引 1
return this.heap[1];
}
// 增,向堆中插入一个元素,时间复杂度 O(logN)
SimpleMinPQ.prototype.push = function(x) {
// 把新元素放到最后
this.heap[++this.size] = x;
// 然后上浮到正确位置
this.swim(this.size);
}
// 删,删除堆顶元素,时间复杂度 O(logN)
SimpleMinPQ.prototype.pop = function() {
var res = this.heap[1];
// 把堆底元素放到堆顶
this.heap[1] = this.heap[this.size--];
// 然后下沉到正确位置
this.sink(1);
return res;
}
// 上浮操作,时间复杂度是树高 O(logN)
SimpleMinPQ.prototype.swim = function(x) {
while (x > 1 && this.heap[this.parent(x)] > this.heap[x]) {
this.swap(this.parent(x), x);
x = this.parent(x);
}
}
// 下沉操作,时间复杂度是树高 O(logN)
SimpleMinPQ.prototype.sink = function(x) {
while (this.left(x) <= this.size || this.right(x) <= this.size) {
var min = x;
if (this.left(x) <= this.size && this.heap[this.left(x)] < this.heap[min]) {
min = this.left(x);
}
if (this.right(x) <= this.size && this.heap[this.right(x)] < this.heap[min]) {
min = this.right(x);
}
if (min == x) {
break;
}
this.swap(x, min);
x = min;
}
}完善版优先级队列
基于上面的简化版优先级队列,只要加上泛型、自定义比较器、扩容等功能,就可以实现一个比较完善的优先级队列了。
我这里只提供 Java 代码,其他语言可以根据上面的思路自行实现:
import java.util.Comparator;
import java.util.NoSuchElementException;
public class MyPriorityQueue<T> {
private T[] heap;
private int size;
private final Comparator<? super T> comparator;
@SuppressWarnings("unchecked")
public MyPriorityQueue(int capacity, Comparator<? super T> comparator) {
heap = (T[]) new Object[capacity + 1]; // 索引 0 空着不用,所以多分配一个空间
size = 0;
this.comparator = comparator;
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
// 父节点的索引
private int parent(int node) {
return node / 2;
}
// 左子节点的索引
private int left(int node) {
return node * 2;
}
// 右子节点的索引
private int right(int node) {
return node * 2 + 1;
}
// 交换数组的两个元素
private void swap(int i, int j) {
T temp = heap[i];
heap[i] = heap[j];
heap[j] = temp;
}
// 查,返回堆顶元素,时间复杂度 O(1)
public T peek() {
if (isEmpty()) {
throw new NoSuchElementException("Priority queue underflow");
}
return heap[1];
}
// 增,向堆中插入一个元素,时间复杂度 O(logN)
public void push(T x) {
// 扩容
if (size == heap.length - 1) {
resize(2 * heap.length);
}
// 把新元素放到最后
heap[++size] = x;
// 然后上浮到正确位置
swim(size);
}
// 删,删除堆顶元素,时间复杂度 O(logN)
public T pop() {
if (isEmpty()) {
throw new NoSuchElementException("Priority queue underflow");
}
T res = heap[1];
// 把堆底元素放到堆顶
swap(1, size--);
// 然后下沉到正确位置
sink(1);
// 避免对象游离
heap[size + 1] = null;
// 缩容
if ((size > 0) && (size == (heap.length - 1) / 4)) {
resize(heap.length / 2);
}
return res;
}
// 上浮操作,时间复杂度是树高 O(logN)
private void swim(int k) {
while (k > 1 && comparator.compare(heap[parent(k)], heap[k]) > 0) {
swap(parent(k), k);
k = parent(k);
}
}
// 下沉操作,时间复杂度是树高 O(logN)
private void sink(int k) {
while (left(k) <= size) {
int j = left(k);
if (j < size && comparator.compare(heap[j], heap[j + 1]) > 0) j++;
if (comparator.compare(heap[k], heap[j]) <= 0) break;
swap(k, j);
k = j;
}
}
// 调整堆的大小
@SuppressWarnings("unchecked")
private void resize(int capacity) {
assert capacity > size;
T[] temp = (T[]) new Object[capacity];
for (int i = 1; i <= size; i++) {
temp[i] = heap[i];
}
heap = temp;
}
public static void main(String[] args) {
MyPriorityQueue<Integer> pq = new MyPriorityQueue<>(3, Comparator.naturalOrder());
pq.push(3);
pq.push(1);
pq.push(4);
pq.push(1);
pq.push(5);
pq.push(9);
while (!pq.isEmpty()) {
System.out.println(pq.pop());
}
}
}