拓展:用栈模拟递归迭代遍历二叉树
本文内容仅作为拓展
我们一般用 递归遍历或者层序遍历的方式 处理二叉树就完全够了。
本文介绍的利用栈迭代遍历二叉树的方法,本质上还是用栈手动模拟递归过程,在本站其他习题中都用不到,面试时也几乎不会有面试官非要难为你写这种代码。
所以本文内容仅作为思维拓展,不要求必须掌握。如果不感兴趣,可以放心地跳过本文的内容。
二叉树的 DFS/BFS 遍历 介绍过二叉树的递归遍历和层序遍历方法,这两种方法是最简单实用的。
有些读者在后台问我如何将前中后序的递归框架改写成迭代形式。我以前背过一些迭代实现二叉树前中后序遍历的代码模板,比较短小,容易记,但通用性较差。
通用性较差的意思是说,模板只是针对「用迭代的方式返回二叉树前/中/后序的遍历结果」这个问题,函数签名类似这样,返回一个 TreeNode 列表:
List<TreeNode> traverse(TreeNode root);vector<TreeNode*> traverse(TreeNode* root);def traverse(root: TreeNode) -> List[TreeNode]:func traverse(root *TreeNode) []*TreeNodevar traverse = function(root) {
};如果给一些稍微复杂的二叉树问题,比如 最近公共祖先,二叉搜索子树的最大键值和,想把这些递归解法改成迭代,就无能为力了。
而我想要的是一个万能的模板,可以把一切二叉树递归算法都改成迭代。
换句话说,类似二叉树的递归框架:
void traverse(TreeNode root) {
if (root == null) return;
// 前序遍历代码位置
traverse(root.left);
// 中序遍历代码位置
traverse(root.right);
// 后序遍历代码位置
}void traverse(TreeNode* root) {
if (root == NULL) return;
// 前序遍历代码位置
traverse(root->left);
// 中序遍历代码位置
traverse(root->right);
// 后序遍历代码位置
}def traverse(root):
if not root:
return
# 前序遍历代码位置
traverse(root.left)
# 中序遍历代码位置
traverse(root.right)
# 后序遍历代码位置func traverse(root *TreeNode) {
if root == nil {
return
}
// 前序遍历代码位置
traverse(root.Left)
// 中序遍历代码位置
traverse(root.Right)
// 后序遍历代码位置
}var traverse = function(root) {
if (root === null) return;
// 前序遍历代码位置
traverse(root.left);
// 中序遍历代码位置
traverse(root.right);
// 后序遍历代码位置
};迭代框架也应该有前中后序代码的位置:
void traverse(TreeNode root) {
while (...) {
if (...) {
// 前序遍历代码位置
}
if (...) {
// 中序遍历代码位置
}
if (...) {
// 后序遍历代码位置
}
}
}void traverse(TreeNode* root) {
while (...) {
if (...) {
// 前序遍历代码位置
}
if (...) {
// 中序遍历代码位置
}
if (...) {
// 后序遍历代码位置
}
}
}def traverse(root: TreeNode):
while (...):
if (...):
# 前序遍历代码位置
if (...):
# 中序遍历代码位置
if (...):
# 后序遍历代码位置func traverse(root *TreeNode) {
for .... {
if ... {
// 前序遍历代码位置
}
if ... {
// 中序遍历代码位置
}
if ... {
// 后序遍历代码位置
}
}
}var traverse = function(root) {
while (...) {
if (...) {
// 前序遍历代码位置
}
if (...) {
// 中序遍历代码位置
}
if (...) {
// 后序遍历代码位置
}
}
}我如果想把递归改成迭代,直接把递归解法中前中后序对应位置的代码复制粘贴到迭代框架里,就可以直接运行,得到正确的结果。
理论上,所有递归算法都可以利用栈改成迭代的形式,因为计算机本质上就是借助栈来迭代地执行递归函数的。
所以本文就来利用「栈」模拟函数递归的过程,总结一套二叉树通用迭代遍历框架。
递归框架改为迭代
按照 二叉树心法(纲领篇) ,二叉树的递归框架中,前中后序遍历位置就是几个特殊的时间点:
前序遍历位置的代码,会在刚遍历到当前节点 root,遍历 root 的左右子树之前执行;
中序遍历位置的代码,会在在遍历完当前节点 root 的左子树,即将开始遍历 root 的右子树的时候执行;
后序遍历位置的代码,会在遍历完以当前节点 root 为根的整棵子树之后执行。
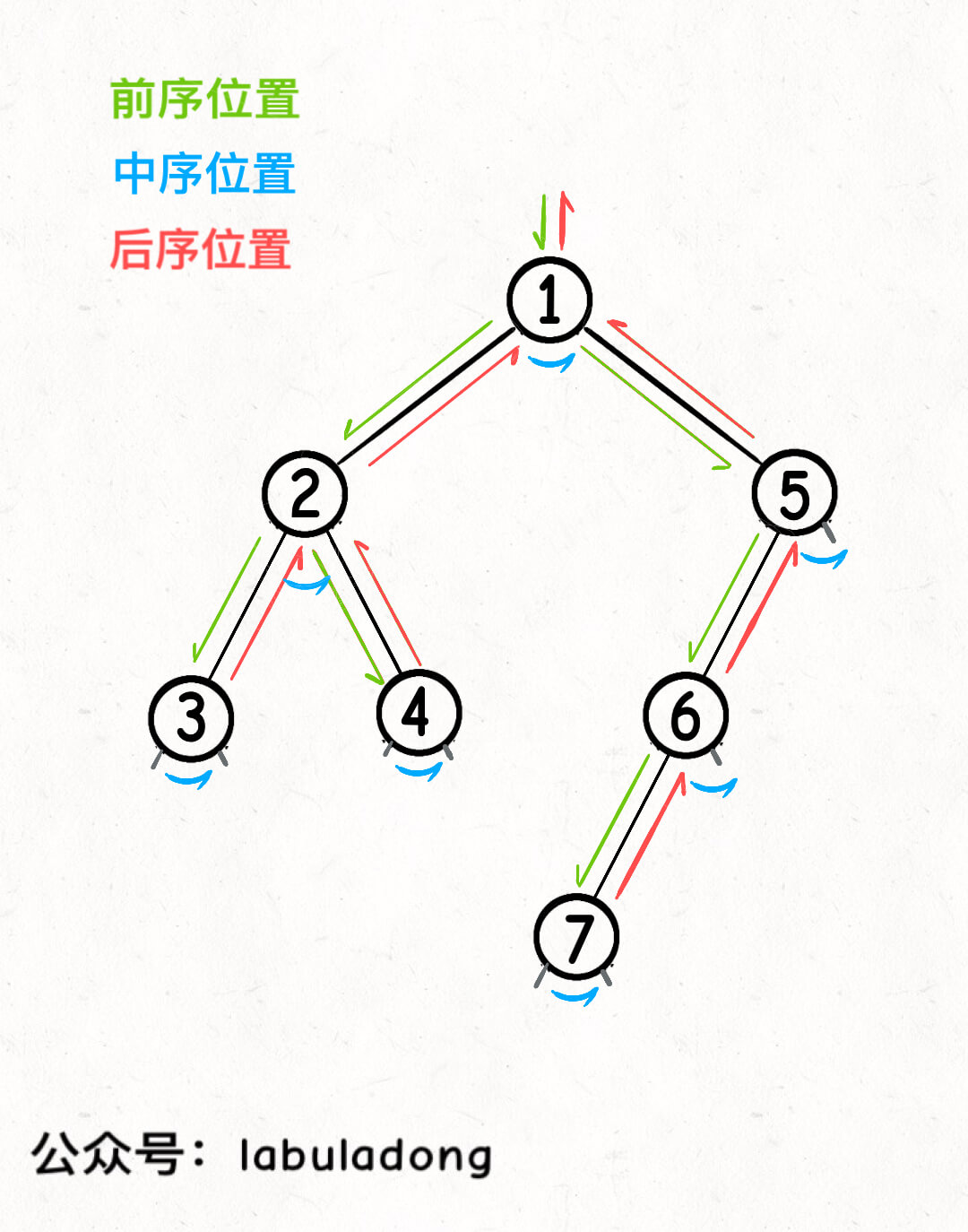
如果从递归代码上来看,上述结论是很容易理解的:
void traverse(TreeNode root) {
if (root == null) return;
// 前序遍历代码位置
traverse(root.left);
// 中序遍历代码位置
traverse(root.right);
// 后序遍历代码位置
}void traverse(TreeNode* root) {
if (root == NULL) return;
// 前序遍历代码位置
traverse(root->left);
// 中序遍历代码位置
traverse(root->right);
// 后序遍历代码位置
}def traverse(root):
if not root:
return
# 前序遍历代码位置
traverse(root.left)
# 中序遍历代码位置
traverse(root.right)
# 后序遍历代码位置func traverse(root *TreeNode) {
if root == nil {
return
}
// 前序遍历代码位置
traverse(root.Left)
// 中序遍历代码位置
traverse(root.Right)
// 后序遍历代码位置
}var traverse = function(root) {
if (root === null) return;
// 前序遍历代码位置
traverse(root.left);
// 中序遍历代码位置
traverse(root.right);
// 后序遍历代码位置
};不过,如果我们想将递归算法改为迭代算法,就不能从框架上理解算法的逻辑,而要深入细节,思考计算机是如何进行递归的。
假设计算机运行函数 A,就会把 A 放到调用栈里面,如果 A 又调用了函数 B,则把 B 压在 A 上面,如果 B 又调用了 C,那就再把 C 压到 B 上面……
当 C 执行结束后,C 出栈,返回值传给 B,B 执行完后出栈,返回值传给 A,最后等 A 执行完,返回结果并出栈,此时调用栈为空,整个函数调用链结束。
我们递归遍历二叉树的函数也是一样的,当函数被调用时,被压入调用栈,当函数结束时,从调用栈中弹出。
那么我们可以写出下面这段代码模拟递归调用的过程:
// 模拟系统的函数调用栈
Stack<TreeNode> stk = new Stack<>();
void traverse(TreeNode root) {
if (root == null) return;
// 函数开始时压入调用栈
stk.push(root);
traverse(root.left);
traverse(root.right);
// 函数结束时离开调用栈
stk.pop();
}#include<stack>
using namespace std;
stack<TreeNode*> stk;
void traverse(TreeNode* root) {
if (root == nullptr) return;
// 函数开始时压入调用栈
stk.push(root);
traverse(root->left);
traverse(root->right);
// 函数结束时离开调用栈
stk.pop();
}# 模拟系统的函数调用栈
stk = []
def traverse(root: TreeNode):
if root is None:
return
# 函数开始时压入调用栈
stk.append(root)
traverse(root.left)
traverse(root.right)
# 函数结束时离开调用栈
stk.pop()func traverse(root *TreeNode) {
// 模拟系统的函数调用栈
var stk []*TreeNode
var dfs func(*TreeNode)
dfs = func(node *TreeNode) {
if node == nil {
return
}
// 函数开始时压入调用栈
stk = append(stk, node)
defer func() {
// 函数结束时离开调用栈
stk = stk[:len(stk)-1]
}()
dfs(node.Left)
dfs(node.Right)
}
dfs(root)
}// 模拟系统的函数调用栈
var stk = [];
function traverse(root) {
if (root === null) return;
// 函数开始时压入调用栈
stk.push(root);
traverse(root.left);
traverse(root.right);
// 函数结束时离开调用栈
stk.pop();
}如果在前序遍历的位置入栈,后序遍历的位置出栈,stk 中的节点变化情况就反映了 traverse 函数的递归过程(GIF 中绿色节点就是被压入栈中的节点,灰色节点就是弹出栈的节点):
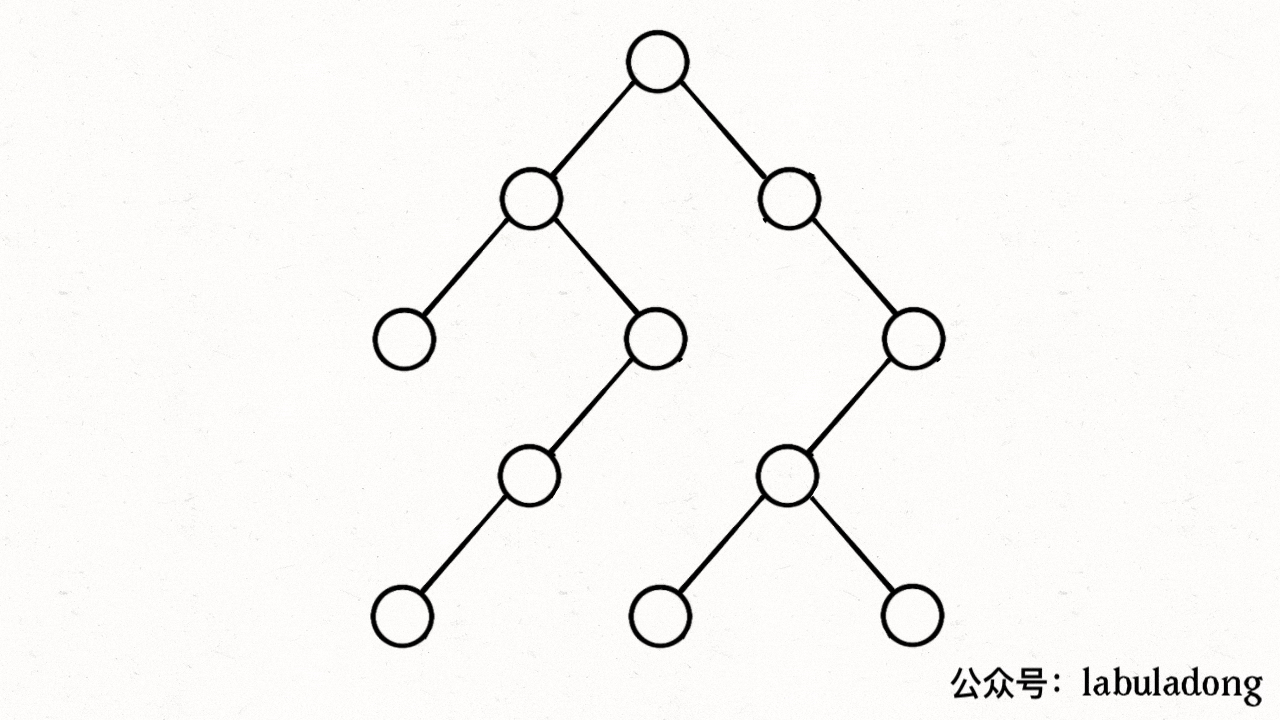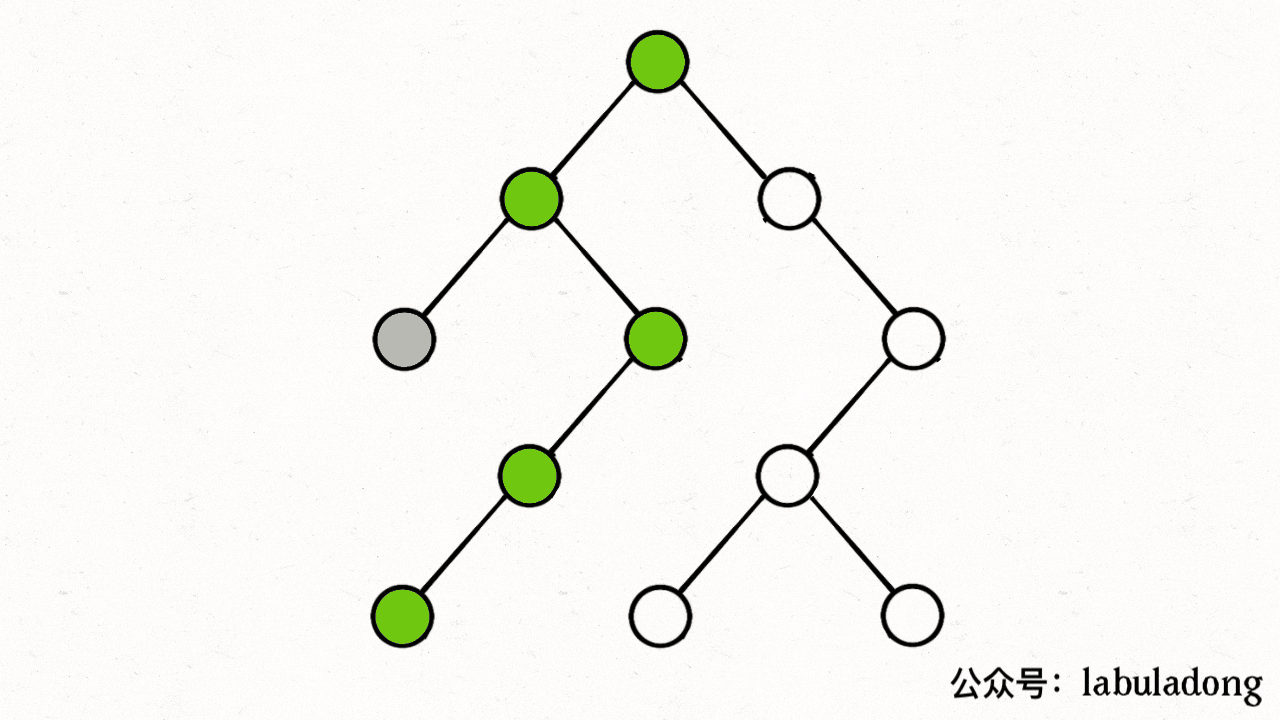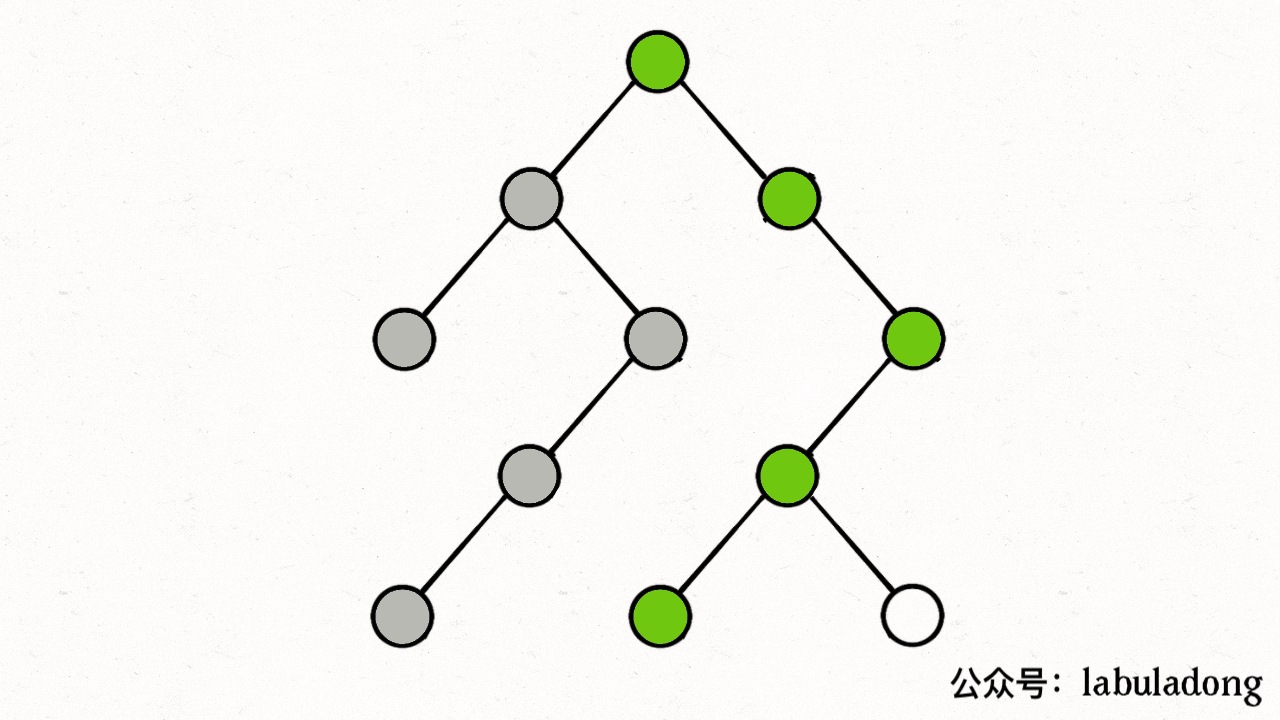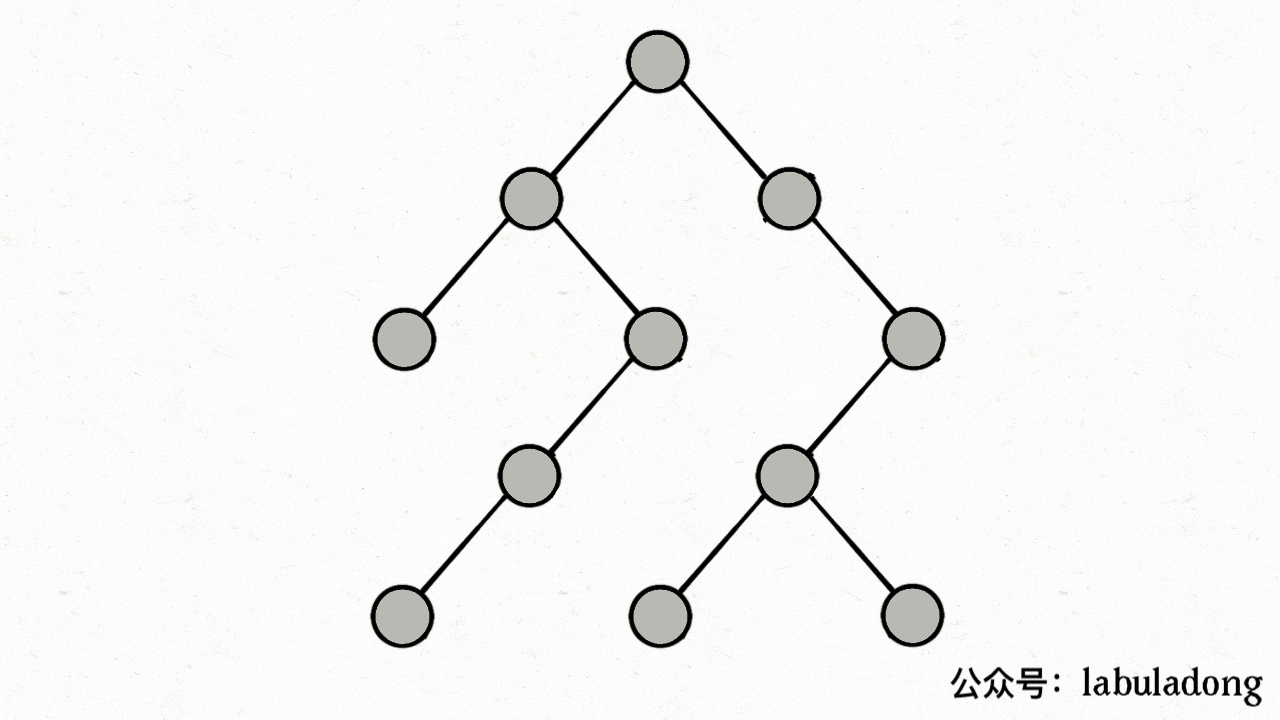
简单说就是这样一个流程:
1、拿到一个节点,就一路向左遍历(因为 traverse(root.left) 排在前面),把路上的节点都压到栈里。
2、往左走到头之后就开始退栈,看看栈顶节点的右指针,非空的话就重复第 1 步。
写成迭代代码就是这样:
class Solution {
private Stack<TreeNode> stk = new Stack<>();
public List<Integer> traverse(TreeNode root) {
pushLeftBranch(root);
while (!stk.isEmpty()) {
TreeNode p = stk.pop();
pushLeftBranch(p.right);
}
}
// 左侧树枝一撸到底,都放入栈中
private void pushLeftBranch(TreeNode p) {
while (p != null) {
stk.push(p);
p = p.left;
}
}
}class Solution {
private:
stack<TreeNode*> stk;
public:
vector<int> traverse(TreeNode* root) {
pushLeftBranch(root);
while (!stk.empty()) {
TreeNode* p = stk.top();
stk.pop();
pushLeftBranch(p->right);
}
}
// 左侧树枝一撸到底,都放入栈中
void pushLeftBranch(TreeNode* p) {
while (p != nullptr) {
stk.push(p);
p = p->left;
}
}
};class Solution:
def __init__(self):
# 初始化一个栈
self.stk = []
def traverse(self, root: TreeNode) -> List[int]:
# 遍历左侧树枝
self.pushLeftBranch(root)
# 当栈不为空时,执行循环操作
while self.stk:
# 取出栈顶元素,即最左侧的子节点
p = self.stk.pop()
# 遍历该节点的右子树的左侧树枝
self.pushLeftBranch(p.right)
# 左侧树枝一撸到底,都放入栈中
def pushLeftBranch(self, p: TreeNode) -> None:
while p:
self.stk.append(p)
p = p.leftfunc traverse(root *TreeNode) []int {
stk := stack.New()
pushLeftBranch(stk, root)
res := make([]int, 0)
// 不断地将左侧树枝入栈,再在弹出节点的时候,将右侧树枝尝试入栈
for stk.Len() != 0 {
p := stk.Pop().(*TreeNode)
res = append(res, p.Val)
pushLeftBranch(stk, p.Right)
}
return res
}
// 左侧树枝入栈,不断找 p 的左节点
func pushLeftBranch(stk *stack.Stack, p *TreeNode) {
for p != nil {
stk.Push(p)
p = p.Left
}
}var traverse = function(root) {
const stk = [];
pushLeftBranch(root);
while (stk.length) {
const p = stk.pop();
pushLeftBranch(p.right);
}
// 左侧树枝一撸到底,都放入栈中
function pushLeftBranch(p) {
while (p) {
stk.push(p);
p = p.left;
}
}
};上述代码虽然已经可以模拟出递归函数的运行过程,不过还没有找到递归代码中的前中后序代码位置,所以需要进一步修改。
迭代代码框架
想在迭代代码中体现前中后序遍历,关键点在哪里?
当我从栈中拿出一个节点 p,我应该想办法搞清楚这个节点 p 左右子树的遍历情况。
如果 p 的左右子树都没有被遍历,那么现在对 p 进行操作就属于前序遍历代码。
如果 p 的左子树被遍历过了,而右子树没有被遍历过,那么现在对 p 进行操作就属于中序遍历代码。
如果 p 的左右子树都被遍历过了,那么现在对 p 进行操作就属于后序遍历代码。
上述逻辑写成伪码如下:
class Solution {
private Stack<TreeNode> stk = new Stack<>();
public List<Integer> traverse(TreeNode root) {
pushLeftBranch(root);
while (!stk.isEmpty()) {
TreeNode p = stk.peek();
if (p 的左子树被遍历完了) {
// *****************
// * 中序遍历代码位置 *
// *****************
pushLeftBranch(p.right);
// 去遍历 p 的右子树
}
if (p 的右子树被遍历完了) {
// *****************
// * 后序遍历代码位置 *
// *****************
stk.pop();
// 以 p 为根的树遍历完了,出栈
}
}
}
private void pushLeftBranch(TreeNode p) {
while (p != null) {
// *****************
// * 前序遍历代码位置 *
// *****************
stk.push(p);
p = p.left;
}
}
}class Solution {
private:
stack<TreeNode*> stk;
public:
vector<int> traverse(TreeNode* root) {
pushLeftBranch(root);
vector<int> result;
while (!stk.empty()) {
TreeNode* p = stk.top();
if (p->left == nullptr) {
// *****************
// * 中序遍历代码位置 *
// *****************
// 去遍历 p 的右子树
stk.pop();
pushLeftBranch(p->right);
}
else if (p->right == nullptr) {
// *****************
// * 后序遍历代码位置 *
// *****************
// 以 p 为根的树遍历完了,出栈
stk.pop();
result.push_back(p->val);
}
else {
stk.pop();
stk.push(p);
pushLeftBranch(p->right);
pushLeftBranch(p->left);
}
}
return result;
}
void pushLeftBranch(TreeNode* p) {
while (p != nullptr) {
// *****************
// * 前序遍历代码位置 *
// *****************
stk.push(p);
p = p->left;
}
}
};class Solution:
def __init__(self):
self.stk = []
def traverse(self, root: TreeNode) -> List[int]:
self.pushLeftBranch(root)
while self.stk:
p = self.stk[-1]
if p.左子树被遍历完了:
# *****************
# * 中序遍历代码位置 *
# *****************
self.pushLeftBranch(p.right)
if p.右子树被遍历完了:
# *****************
# * 后序遍历代码位置 *
# *****************
self.stk.pop()
def pushLeftBranch(self, p: TreeNode) -> None:
while p:
# *****************
# * 前序遍历代码位置 *
# *****************
self.stk.append(p)
p = p.leftfunc traverse(root *TreeNode) []int {
var stk []*TreeNode
pushLeftBranch(&stk, root)
var result []int
for len(stk) != 0 {
p := stk[len(stk)-1]
if p.Left == nil {
// *****************
// * 中序遍历代码位置 *
// *****************
result = append(result, p.Val)
stk = stk[:len(stk)-1]
if p.Right != nil {
pushLeftBranch(&stk, p.Right)
}
} else if root == p.Left {
// *****************
// * 前序遍历代码位置 *
// *****************
result = append(result, p.Val)
if p.Right != nil {
pushLeftBranch(&stk, p.Right)
}
} else {
// *****************
// * 后序遍历代码位置 *
// *****************
stk = stk[:len(stk)-1]
result = append(result, p.Val)
}
}
return result
}
func pushLeftBranch(stk *[]*TreeNode, p *TreeNode) {
for p != nil {
(*stk) = append((*stk), p)
p = p.Left
}
}var traverse = function(root) {
var stk = [];
pushLeftBranch(root);
while (stk.length > 0) {
var p = stk[stk.length - 1];
if (p.的左子树被遍历完了) {
// *****************
// * 中序遍历代码位置 *
// *****************
// 去遍历 p 的右子树
pushLeftBranch(p.right);
}
if (p.的右子树被遍历完了) {
// *****************
// * 后序遍历代码位置 *
// *****************
// 以 p 为根的树遍历完了,出栈
stk.pop();
}
}
function pushLeftBranch(p) {
while (p !== null) {
// *****************
// * 前序遍历代码位置 *
// *****************
stk.push(p);
p = p.left;
}
}
};有刚才的铺垫,这段代码应该是不难理解的,关键是如何判断 p 的左右子树到底被遍历过没有呢?
其实很简单,我们只需要维护一个 visited 指针,指向「上一次遍历完成的根节点」,就可以判断 p 的左右子树遍历情况了
下面是迭代遍历二叉树的完整代码框架:
class Solution {
// 模拟函数调用栈
private Stack<TreeNode> stk = new Stack<>();
// 左侧树枝一撸到底
private void pushLeftBranch(TreeNode p) {
while (p != null) {
// *****************
// * 前序遍历代码位置 *
// *****************
stk.push(p);
p = p.left;
}
}
public List<Integer> traverse(TreeNode root) {
// 指向上一次遍历完的子树根节点
TreeNode visited = new TreeNode(-1);
// 开始遍历整棵树
pushLeftBranch(root);
while (!stk.isEmpty()) {
TreeNode p = stk.peek();
// p 的左子树被遍历完了,且右子树没有被遍历过
if ((p.left == null || p.left == visited)
&& p.right != visited) {
// *****************
// * 中序遍历代码位置 *
// *****************
// 去遍历 p 的右子树
pushLeftBranch(p.right);
}
// p 的右子树被遍历完了
if (p.right == null || p.right == visited) {
// *****************
// * 后序遍历代码位置 *
// *****************
// 以 p 为根的子树被遍历完了,出栈
// visited 指针指向 p
visited = stk.pop();
}
}
}
}class Solution {
private:
// 模拟函数调用栈
stack<TreeNode*> stk;
// 左侧树枝一撸到底
void pushLeftBranch(TreeNode* p) {
while (p != nullptr) {
// *****************
// * 前序遍历代码位置 *
// *****************
stk.push(p);
p = p->left;
}
}
public:
vector<int> traverse(TreeNode* root) {
// 指向上一次遍历完的子树根节点
TreeNode* visited = new TreeNode(-1);
// 开始遍历整棵树
pushLeftBranch(root);
while (!stk.empty()) {
TreeNode* p = stk.top();
// p 的左子树被遍历完了,且右子树没有被遍历过
if ((p->left == nullptr || p->left == visited)
&& p->right != visited) {
// *****************
// * 中序遍历代码位置 *
// *****************
// 去遍历 p 的右子树
pushLeftBranch(p->right);
}
// p 的右子树被遍历完了
if (p->right == nullptr || p->right == visited) {
// *****************
// * 后序遍历代码位置 *
// *****************
// 以 p 为根的子树被遍历完了,出栈
// visited 指针指向 p
visited = p;
stk.pop();
}
}
}
};class Solution:
def __init__(self):
# 模拟函数调用栈
self.stk = []
# 左侧树枝一撸到底
def pushLeftBranch(self, p):
while p:
# 前序遍历代码位置
self.stk.append(p)
p = p.left
def traverse(self, root: TreeNode) -> List[int]:
# 指向上一次遍历完的子树根节点
visited = TreeNode(-1)
# 开始遍历整棵树
self.pushLeftBranch(root)
res = []
while self.stk:
p = self.stk[-1]
# p 的左子树被遍历完了,且右子树没有被遍历过
if (not p.left or p.left == visited) and (not p.right or p.right != visited):
# 中序遍历代码位置
res.append(p.val)
# 去遍历 p 的右子树
self.pushLeftBranch(p.right)
# p 的右子树被遍历完了
if not p.right or p.right == visited:
# 后序遍历代码位置
# 以 p 为根的子树被遍历完了,出栈
# visited 指针指向 p
visited = self.stk.pop()
return restype Stack struct {
data []*TreeNode
}
func (s *Stack) Push(x *TreeNode) {
s.data = append(s.data, x)
}
func (s *Stack) Pop() *TreeNode {
if len(s.data) == 0 {
return nil
}
x := s.data[len(s.data)-1]
s.data = s.data[:len(s.data)-1]
return x
}
func (s *Stack) Peek() *TreeNode {
if len(s.data) == 0 {
return nil
}
return s.data[len(s.data)-1]
}
func traverse(root *TreeNode) []int {
var res []int
stk := new(Stack)
visited := &TreeNode{Val: -1}
// 开始遍历整棵树
pushLeftBranch(stk, root)
for !isEmpty(stk) {
p := peek(stk)
if (p.Left == nil || p.Left == visited) && p.Right != visited {
// 中序遍历代码位置
pushLeftBranch(stk, p.Right)
}
if p.Right == nil || p.Right == visited {
// 后序遍历代码位置
visited = pop(stk)
res = append(res, visited.Val)
}
}
return res
}
func pushLeftBranch(stk *Stack, p *TreeNode) {
for p != nil {
// 前序遍历代码位置
stk.Push(p)
p = p.Left
}
}
func peek(stk *Stack) *TreeNode {
return stk.Peek()
}
func pop(stk *Stack) *TreeNode {
return stk.Pop()
}
func isEmpty(stk *Stack) bool {
return len(stk.data) == 0
}var traverse = function(root) {
var stk = new Stack();
var pushLeftBranch = function(p) {
while (p != null) {
// *****************
// * 前序遍历代码位置 *
// *****************
stk.push(p);
p = p.left;
}
};
// 指向上一次遍历完的子树根节点
var visited = new TreeNode(-1);
// 开始遍历整棵树
pushLeftBranch(root);
while (!stk.isEmpty()) {
var p = stk.peek();
// p 的左子树被遍历完了,且右子树没有被遍历过
if ((p.left == null || p.left == visited)
&& p.right != visited) {
// *****************
// * 中序遍历代码位置 *
// *****************
// 去遍历 p 的右子树
pushLeftBranch(p.right);
}
// p 的右子树被遍历完了
if (p.right == null || p.right == visited) {
// *****************
// * 后序遍历代码位置 *
// *****************
// 以 p 为根的子树被遍历完了,出栈
// visited 指针指向 p
visited = stk.pop();
}
}
};代码中最有技巧性的是这个 visited 指针,它记录最近一次遍历完的子树根节点(最近一次 pop 出栈的节点),我们可以根据对比 p 的左右指针和 visited 是否相同来判断节点 p 的左右子树是否被遍历过,进而分离出前中后序的代码位置。
提示
visited 指针初始化指向一个新 new 出来的二叉树节点,相当于一个特殊值,目的是避免和输入二叉树中的节点重复。
只需把递归算法中的前中后序位置的代码复制粘贴到上述框架的对应位置,就可以把任意递归的二叉树算法改写成迭代形式了。
比如,让你返回二叉树后序遍历的结果,你就可以这样写:
class Solution {
private Stack<TreeNode> stk = new Stack<>();
public List<Integer> postorderTraversal(TreeNode root) {
// 记录后序遍历的结果
List<Integer> postorder = new ArrayList<>();
TreeNode visited = new TreeNode(-1);
pushLeftBranch(root);
while (!stk.isEmpty()) {
TreeNode p = stk.peek();
if ((p.left == null || p.left == visited)
&& p.right != visited) {
pushLeftBranch(p.right);
}
if (p.right == null || p.right == visited) {
// 后序遍历代码位置
postorder.add(p.val);
visited = stk.pop();
}
}
return postorder;
}
private void pushLeftBranch(TreeNode p) {
while (p != null) {
stk.push(p);
p = p.left;
}
}
}class Solution {
private:
stack<TreeNode*> stk;
public:
vector<int> postorderTraversal(TreeNode* root) {
// 记录后序遍历的结果
vector<int> postorder;
TreeNode* visited = new TreeNode(-1);
pushLeftBranch(root);
while (!stk.empty()) {
TreeNode* p = stk.top();
if ((p->left == nullptr || p->left == visited)
&& p->right != visited) {
pushLeftBranch(p->right);
}
if (p->right == nullptr || p->right == visited) {
// 后序遍历代码位置
postorder.push_back(p->val);
visited = stk.top();
stk.pop();
}
}
return postorder;
}
private:
void pushLeftBranch(TreeNode* p) {
while (p != nullptr) {
stk.push(p);
p = p->left;
}
}
};class Solution:
def __init__(self):
self.stk = []
def postorderTraversal(self, root: TreeNode) -> List[int]:
# 记录后序遍历的结果
postorder = []
visited = TreeNode(-1)
self.pushLeftBranch(root)
while len(self.stk) != 0:
p = self.stk[-1]
if (p.left == None or p.left == visited) and p.right != visited:
self.pushLeftBranch(p.right)
if p.right == None or p.right == visited:
# 后序遍历代码位置
postorder.append(p.val)
visited = self.stk.pop()
return postorder
def pushLeftBranch(self, p):
while p != None:
self.stk.append(p)
p = p.left// 迭代写法
func postorderTraversal(root *TreeNode) []int {
stk := []*TreeNode{}
postorder := []int{}
visited := &TreeNode{Val: -1}
// 先推入左子树节点
pushLeftBranch(root, &stk)
for len(stk) > 0 {
p := stk[len(stk) - 1]
if (p.Left == nil || p.Left == visited) && p.Right != visited {
// 左子树不为空,且左子树未被访问,推入右子树左节点
pushLeftBranch(p.Right, &stk)
}
if p.Right == nil || p.Right == visited {
// 左右子树都已经访问过了,说明该节点应该被加入到后序遍历集合中
postorder = append(postorder, p.Val)
visited = stk[len(stk) - 1]
stk = stk[:len(stk) - 1]
}
}
return postorder
}
func pushLeftBranch(node *TreeNode, stk *[]*TreeNode) {
for node != nil {
*stk = append(*stk, node)
node = node.Left
}
}var postorderTraversal = function(root) {
// 创建一个栈,用于遍历节点
const stk = [];
// 创建一个列表,用于记录后序遍历结果
const postorder = [];
// 定义一个标志节点
let visited = new TreeNode(-1);
// 将左分支依次入栈
pushLeftBranch(root);
while (stk.length > 0) {
// 获取栈顶节点
let node = stk[stk.length - 1];
if ((node.left === null || node.left === visited) && (node.right !== visited)) {
// 当前节点左子树已经遍历,右子树未遍历,则遍历右子树
pushLeftBranch(node.right);
}
if ((node.right === null || node.right === visited)) {
// 当前节点的右子树已经遍历,当前节点即将出栈
postorder.push(node.val);
visited = stk.pop();
}
}
// 向左依次遍历,将左分支节点入栈
function pushLeftBranch(node) {
while (node !== null) {
stk.push(node);
node = node.left;
}
}
return postorder;
};当然,任何一个二叉树的算法,如果你想把递归改成迭代,都可以套用这个框架,只要把递归的前中后序位置的代码对应过来就行了。
迭代解法到这里就搞定了,不过我还是想强调,除了 BFS 层级遍历之外,二叉树的题目还是用递归的方式来做,因为递归是最符合二叉树结构特点的。
说到底,这个迭代解法就是在用栈模拟递归调用,所以对照着递归解法,应该不难理解和记忆。
本文就到这里,更多经典的二叉树习题以及递归思维的训练,请参见二叉树章节中的 递归专项练习。
引用本文的题目
安装 我的 Chrome 刷题插件 点开下列题目可直接查看解题思路:
| LeetCode | 力扣 | 难度 |
|---|---|---|
| 173. Binary Search Tree Iterator | 173. 二叉搜索树迭代器 | 🟠 |
| - | 剑指 Offer II 055. 二叉搜索树迭代器 | 🟠 |
