解答回溯算法/DFS算法的若干疑问
本文用最简单的示例,一次性解答读者关于回溯算法、DFS 算法的若干疑问。
回溯算法和 DFS 算法有何区别?
经常有读者问我,网站上为啥只写了回溯算法,却没有写过 DFS 算法呢?
还有些读者有疑问,回溯算法核心框架 中说到回溯算法模板是在递归前做选择,递归后撤销选择,即这样:
void backtrack(...) {
if (到达叶子节点) {
return;
}
for (int i = 0; i < n; i++) {
// 做选择
...
backtrack(...)
// 撤销选择
...
}
}但是为什么有些时候会看到代码在 for 循环的前面「做选择」,在 for 循环的后面「撤销选择」呢:
void backtrack(...) {
if (到达叶子节点) {
return;
}
// 做选择
...
for (int i = 0, i < n; i++) {
backtrack(...)
}
// 撤销选择
...
}这两种写法的区别是什么?
答疑
我先来回答第二个问题,为什么你会看到两种写法?它们有何区别?
第一种写法是标准的回溯算法框架,第二种写法,如果非要区分的话,它其实应该归为 DFS 算法框架。
你完全可以给递归函数换个名字,这样更容易区别:
// 回溯算法框架模板
void backtrack(...) {
if (到达叶子节点) {
return;
}
for (int i = 0; i < n; i++;) {
// 做选择
...
backtrack(...)
// 撤销选择
...
}
}
// DFS 算法框架模板
void dfs(...) {
if (到达叶子节点) {
return;
}
// 做选择
...
for (int i = 0; i < n; i++) {
dfs(...)
}
// 撤销选择
...
}再回答第一个问题,回溯算法和 DFS 算法有何区别?
依据 二叉树系列算法(纲领篇) 的总结,它俩的本质是一样的,都是「遍历」思维下的暴力穷举算法。唯一的区别在于关注点不同,回溯算法的关注点在「树枝」,DFS 算法的关注点在「节点」。
我用最简单的多叉树遍历代码来举例说明回溯算法和 DFS 算法的区别,这是遍历多叉树的代码:
void traverse(Node root) {
if (root == null) {
return;
}
for (Node child : root.children) {
traverse(child);
}
}这个多叉树遍历函数,可以变化成回溯算法框架,也可以变化成 DFS 算法框架。
比方我想让他变成回溯算法,那么就是这样:
void backtrack(Node root) {
if (root == null) {
return;
}
for (Node child : root.children) {
// 做选择
printf("我在 %s 和 %s 中间的树枝上做选择", root, child);
backtrack(child);
// 撤销选择
printf("我在 %s 和 %s 中间的树枝上撤销选择", root, child);
}
}如果我想让他变成 DFS 算法,那么就是这样:
void dfs(Node root) {
if (root == null) {
return;
}
// 做选择
printf("我在 %s 节点上做选择", root);
for (Node child : root.children) {
dfs(child);
}
// 撤销选择
printf("我在 %s 节点上撤销选择", root);
}所以你说它俩有啥本质区别么?其实没有。无非就是按照题目的需求,我们灵活运用罢了。
比方说现在题目让你把多叉树上的每个节点都打印出来,那么你就用 DFS 算法框架呗:
void dfs(Node root) {
if (root == null) {
return;
}
print(root.val);
for (Node child : root.children) {
dfs(child);
}
}如果你非要把这个 print 代码写到 for 循环里面,那么最终打印出来的结果就会漏掉整棵树的根节点:
void backtrack(Node root) {
if (root == null) {
return;
}
for (Node child : root.children) {
// 非要这样写的话,这棵树的根节点会被漏掉
print(child.val);
backtrack(child);
}
}当然你如果非要这样写也不是不行,在调用 backtrack 函数之前,单独处理一下根节点就可以了,只不过有些麻烦罢了。
那么对于排列组合这种经典问题,它们的关注点显然就是在树枝上的,你注意我在前文 回溯算法秒杀排列组合的九种变体 中画的图,都是有深意的:
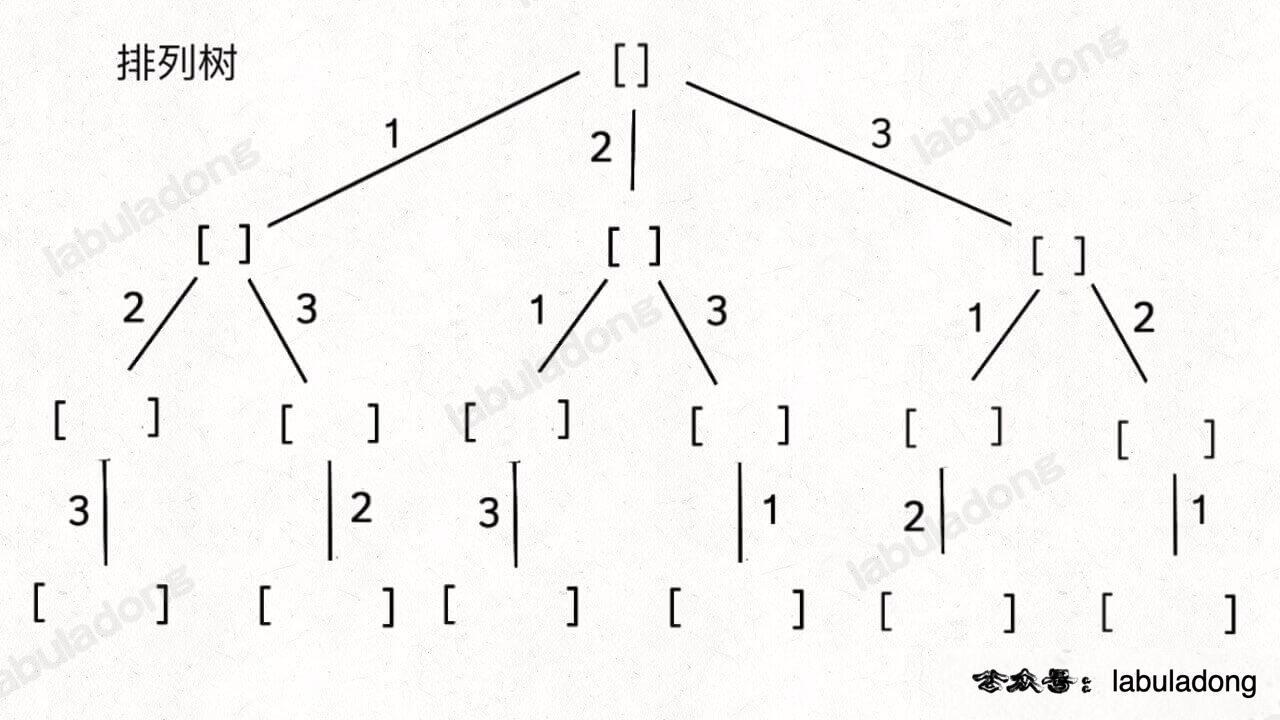
图中的数字,为啥画在树枝上而不是节点上?因为你在穷举排列组合的时候,就是在树枝位置做选择(往 track 里面添加的元素),节点中反映的是你此次选择的结果(track 的状态):
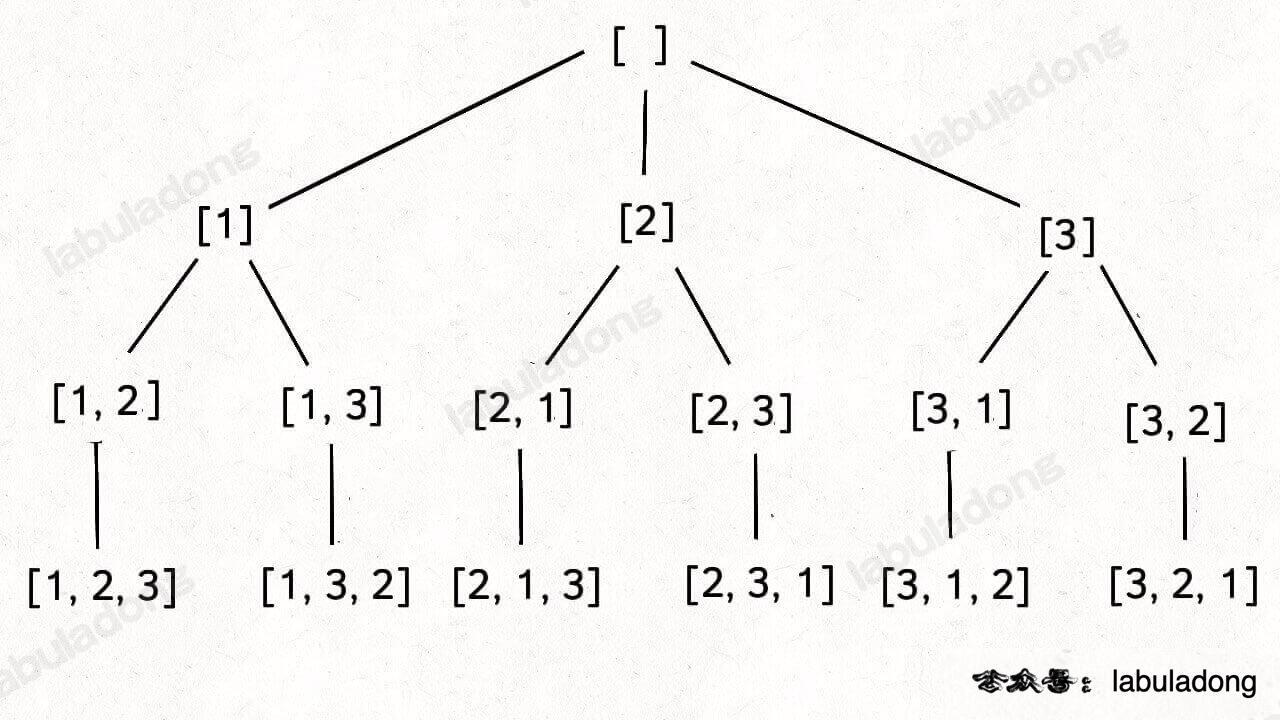
结合代码理解下:
LinkedList<Integer> track = new LinkedList<>();
// 回溯算法核心函数
void backtrack(int[] nums) {
// 回溯算法标准框架
for (int i = 0; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
// 进入下一层回溯树
backtrack(nums);
// 取消选择
track.removeLast();
}
}懂了吧?所以我一般把 DFS 和回溯默认为同一种算法,我们根据题目的需求,灵活选用即可。
backtrack/dfs/traverse 函数可以有返回值吗?
先说结论
理论上你随意,但是我强烈建议,对于 backtrack/dfs/traverse 函数,就作为单纯的遍历函数,请保持 void 类型,不要给它们带返回值。
我知道给这种遍历函数加返回值是为了提前终止递归,但有更清晰的方法做到这一点,下面会讲。
依据 二叉树系列算法(纲领篇) 的总结,递归算法主要有两种思维模式,一种是「遍历」的思维,一种是「分解问题」的思维。
分解问题的思维模式大概率是有返回值的,因为要根据子问题的结果来计算当前问题的结果。这种函数的名字我们一般也要取得有意义,比如 int maxDepth(TreeNode root),一眼就能看出来这个函数的返回值是什么含义。
而遍历的思维模式,我们习惯上就会创建一个名为 backtrack/dfs/traverse 的函数,它本身只起到遍历多叉树的作用,简单明了。如果再搅合进去一个返回值,意思是你这个函数有特殊的定义?那么请问你的思路到底是遍历还是分解问题?功力不到位的话,很容易把自己绕进去,写着写着自己都不知道这个返回值该咋用了。
我随口编一道简单的题目作为具体的例子:输入一棵二叉树根节点和一个 targetVal,请你在这棵树中找到任意一个值为 targetVal 的节点,如果不存在,返回 null。
函数签名如下:
TreeNode findTarget(TreeNode root, int targetVal);这个题很简单吧,可以同时用「遍历」和「分解问题」的思维解决。
如果用「分解问题」的思维,那么解法代码就是这样的:
// 定义:输入节点 root 和目标值 targetVal,返回以 root 为根的树中值为 targetVal 的那个节点
TreeNode findTarget(TreeNode root, int targetVal) {
// base case
if (root == null) {
return null;
}
if (root.val == targetVal) {
return root;
}
// 利用定义,去左子树中寻找
TreeNode leftResult = findTarget(root.left, targetVal);
if (leftResult != null) {
return leftResult;
}
// 如果左子树中没有,再利用定义,去右子树中寻找
TreeNode rightResult = findTarget(root.right, targetVal);
if (rightResult != null) {
return rightResult;
}
return null;
}如果用「遍历」的思维,那么可能有读者就会写出这样的代码:
// 记录答案
TreeNode res = null;
TreeNode findTarget(TreeNode root, int targetVal) {
traverse(root, targetVal);
return res;
}
// 不推荐这样写
boolean traverse(TreeNode root, int targetVal) {
if (root == null) {
return false;
}
if (root.val == targetVal) {
res = root;
return true;
}
return traverse(root.left, targetVal) || traverse(root.right, targetVal);
}其实这个代码是正确的,但是理解成本就有点高了。
我就会疑惑,你的 traverse 函数为啥会有返回值呢?既然有返回值,你这是分解问题的思路吗?也不太像,并没有见你利用这个返回值,来推导出原问题的结果呀。
仔细看看才明白,原来这个 bool 类型的返回值,是为了在找到一个合法答案后终止递归,减少冗余计算的。
那么我推荐的写法是什么呢?就是各司其职,traverse 函数就起到遍历的作用,不要带返回值,至于是否找到了答案,由外部变量控制。
比方说你可以添加一个 found 外部变量,或者干脆利用 res 变量是否为 null 来判断是否找到了答案:
// 记录答案
TreeNode res = null;
TreeNode findTarget(TreeNode root, int targetVal) {
traverse(root, targetVal);
return res;
}
// 标准二叉树遍历框架
void traverse(TreeNode root, int targetVal) {
if (root == null) {
return;
}
if (res != null) {
// 已经找到一个答案了,直接返回,终止递归
return;
}
if (root.val == targetVal) {
res = root;
return;
}
// 标准遍历框架,遍历二叉树的所有结点
traverse(root.left, targetVal);
traverse(root.right, targetVal);
}好了,这样一写就很清楚,我知道你的 traverse 函数仅用来遍历二叉树,具体的处理逻辑,我会去研究前中后序位置上的代码。
这就是一个简单的例子,但所有利用「遍历」思维的递归函数,都是相同的道理。尤其是当题目只让你寻找一个合法答案时,建议保持遍历函数的 void 类型,用外部变量来控制递归的终止。
base case 和剪枝应该写在哪里?
这个问题是啥意思呢,就比如说最简单的二叉树的遍历框架,我一般是这样写的:
void traverse(TreeNode root) {
// base case
if (root == null) {
return;
}
// 前序位置
traverse(root.left);
// 中序位置
traverse(root.right);
// 后序位置
}那有些读者可能会这样写:
void traverse(TreeNode root) {
if (root!= null && root.left != null) {
traverse(root.left);
}
if (root!= null && root.right != null) {
traverse(root.right);
}
}这两种写法当然都可以啦,但是我的一般习惯是,把能提到函数开头的判断逻辑都提到函数开头,因为递归部分是填写前中后序代码的位置,尽量不要和 base case 的逻辑混到一起,否则容易混乱。比方上面这种写法,你的前中后序位置是哪里?是不是不太清楚?
不过呢,在我优化回溯算法的时候,会习惯把剪枝逻辑放在递归之前,类似这样:
void backtrack(...) {
// base case
if (到达叶子节点) {
return;
}
for (int i = 0, i < n; i++) {
// 剪枝逻辑
if (第 i 个选择不满足条件) {
continue;
}
// 做选择
...
backtrack(...)
// 撤销选择
...
}
}我觉得这样会更清晰嘛,因为你剪枝减掉的就是无效的选择呀,所以放在做选择之前,就很合理。
但大部分情况,把这个剪枝逻辑移到函数开头和 base case 放在一起其实也可以,所以这个就看个人习惯了,只要答案是正确的,你爱咋写咋写吧。